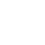清华裴丹: AIOps落地的15条原则
发布时间:2021-10-11 10:44:00

清华大学裴丹教授最近就AIOps落地经验进行了多次分享。本文主要根据裴丹教授在“2021国际AIOps挑战赛决赛暨AIOps创新高峰论坛”、“IDC中国数字金融论坛”的两次演讲稿整理而成。
结合个人过去20年在AIOps领域与几十家企业合作、跨多种技术栈的落地经验积累,以及150篇左右学术论文的算法积累,我将分享个人总结出来的AIOps落地的15条经验性原则。这些经验分成5个大类原则,分别涉及AIOps落地的“大势所趋、价值路线、架构路线、算法路线、生态路线”等五个方面。

原则1 (大势所趋):顺势而为、知己(Ops)知彼(AI)、触类旁通
第一个原则主要讲AIOps是大势所趋,无论是从运维角度,还是从人工智能技术的应用角度和科学技术的应用角度来说都是这样。
原则1.a 顺势而为
运维技术在各行各业的重要性越来越高,像银行、证券、保险、电信、能源、工业制造、政府部门、互联网等。由于各行各业数字化程度越来越高、系统规模越来越大、组件监控粒度越来越细、监控数据量越来越大以及新技术和新组件的不断引入,这些导致运维越来越难做,运维工程师也被海量高速的运维监控数据所淹没。
一方面,运维监控数据是海量的、高速的、多模态的、价值极大的、但又信噪比极低的(即:对运维人员来说直接价值最高的异常数据在数量上远远小于正常数据)。目前看,人工智能算法是处理符合上述特点的数据的最有希望的方法。
另一方面,只有在这些数据被关联起来一起分析时才能发挥出它们最大的价值,而关联需要各类复杂的依赖关系知识(逻辑组件之间的调用关系图、逻辑组件在物理组件上部署关系图、物理组件的网络路径关系图)和专家知识(组件内运维故障间的因果关系图),才能有物理意义地把各类运维信号关联起来进行有效分析。目前看,知识图谱技术是表征和应用这些用图表示的知识的最有希望的方法。
由此可见,用AI方法解决运维挑战,势在必行。

当然,不同用户、不同企业的技术风险喜好程度不一样,因此落地AIOps的节奏会有所不同,但是我希望前面的简要论述已经说明了AIOps是运维领域发展的大势所趋,没有别的选择,我们只能顺势而为,AIOps是运维这一领域必须要做的事情。
原则1.b 知己(Ops)知彼(AI)
在AIOps落地过程中,相关人员对于AIOps的定义、AIOps的本质、AIOps的能力边界都有一些讨论甚至争论。在此我也总结一下我对如上几方面的认知。
我先说一下形成我的认知的方法论:知己(Ops)知彼(AI) 。知己是指我们要充分认识到运维(Ops)领域是一个强领域知识的计算机应用领域,一定要想尽办法把运维领域知识有机结合进来;知彼是指我们要充分认识AI作为一种计算机技术类别的演进趋势,并尊重其在一定时间窗口内的能力边界。
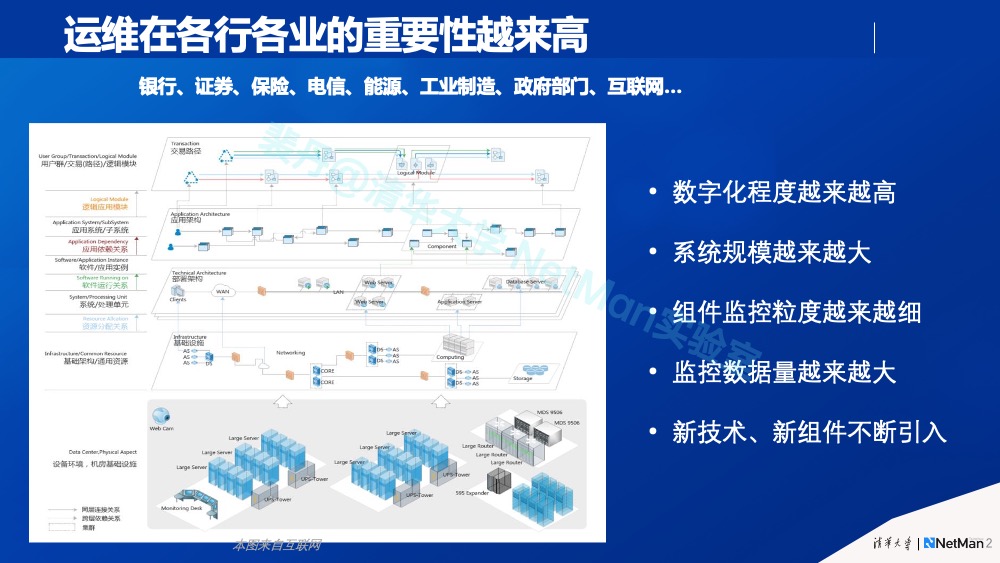
首先,相信大家到现在已经都了解不同运维场景用的技术和算法是不一样的(如下图所示我在清华实验室发表的论文中采用过的基础算法),很难用黑盒方法来做。
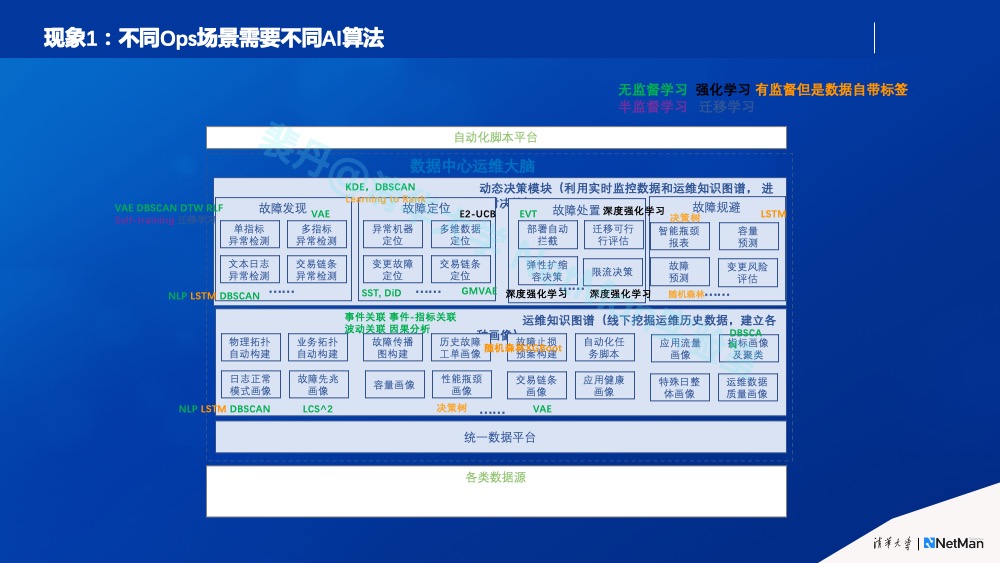
其次,目前为止整个人工智能领域都是智能在非常具体的行业和非常具体的场景中取得的成功。同理这是因为行业不同、场景不同,它所需要的算法和技术就有所不同。
如果把AI比作一种高级编程语言的话,AI应用无非就是在一个软件架构里面提供了一部分组件,其部分程序逻辑总结自数据,是概率性的模糊性的。而任何应用,其逻辑都是领域知识强相关的。就像我们不可能假设学会了Java语言就能自动解决一切应用问题一样,我们一定要针对具体行业、具体场景才可能做好一个AI应用。
因此,我们说的知己,是指要清醒认识到一切运维工具几乎都是基于强运维领域知识的,AIOps也不例外,一定要想尽办法把运维领域知识有机结合进来。
知彼是指我们要充分认识AI作为一种计算机技术类别的演进趋势,并尊重其在一定时间窗口内的能力边界。首先,我们要了解人工智能现在进展到了哪个阶段。引用清华大学计算机系张钹院士的话,“AI并非无所不能,当前AI做得好的事需要同时满足五个条件。”(见下图)

关于AI的发展趋势,我也引用一下张钹院士最新发表的一篇文章里提到的AI最新的方向。AI 1.0是“知识驱动+算法+算力”,这是深蓝计算机打败国际象棋冠军卡斯帕罗夫的那个年代的技术;到后来AI 2.0“数据驱动+算法+算力“,代表性技术是基于深度学习的计算机视觉;AI 3.0是“知识+数据+算法+算力”,融合知识和数据,是未来AI应用的大势所趋。
如前所述,AIOps需要分析关联海量多源多模态运维大数据,因此基于强运维领域知识的AI 3.0 技术也是AIOps发展的必然技术路线。
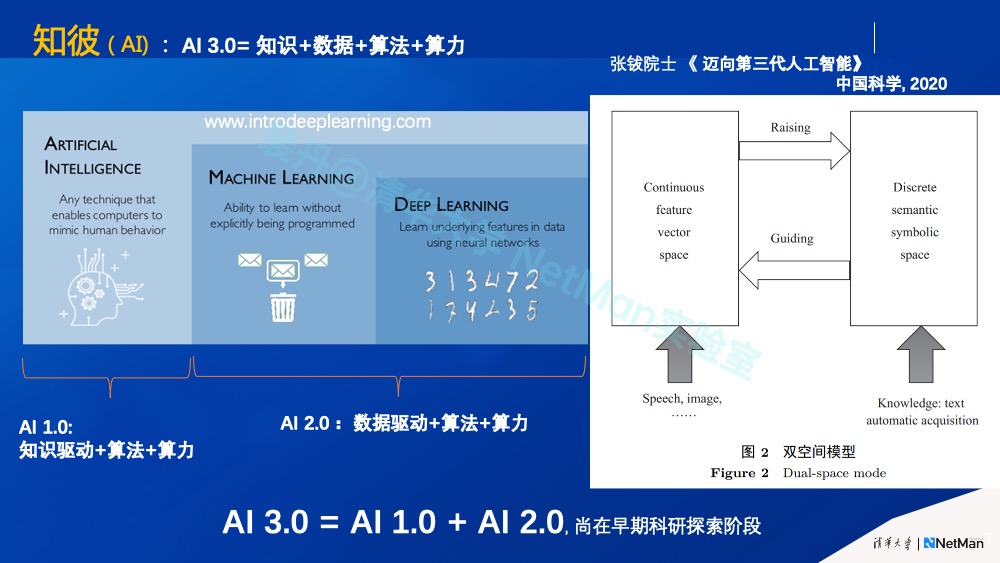
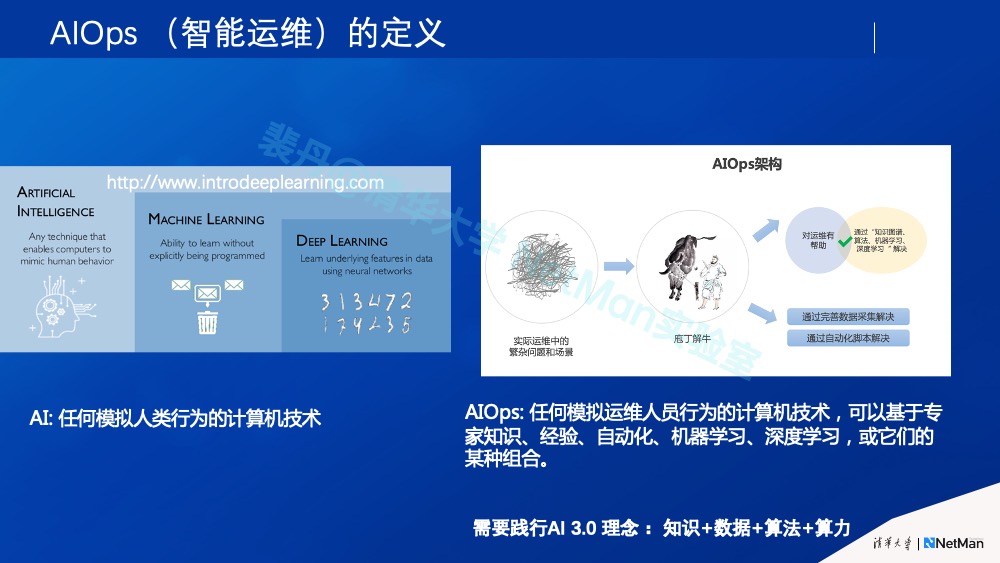
至此,我们可以清晰定义AIOps智能运维(AI+Ops)了。我们说,AI是任何模拟人类行为的计算机技术。AIOps是什么?就是任何模拟运维人员行为的计算机技术,它可以基于专家知识、经验、自动化、机器学习、深度学习或它们的某种组合。从另一个角度说,不要因为用到了自动化或硬逻辑,就判定其不是AI 或AIOps。我们要做的是践行“知识+数据+算法+算力”的AI 3.0概念,这也是AI应用的大势所趋。
原则1.c 触类旁通
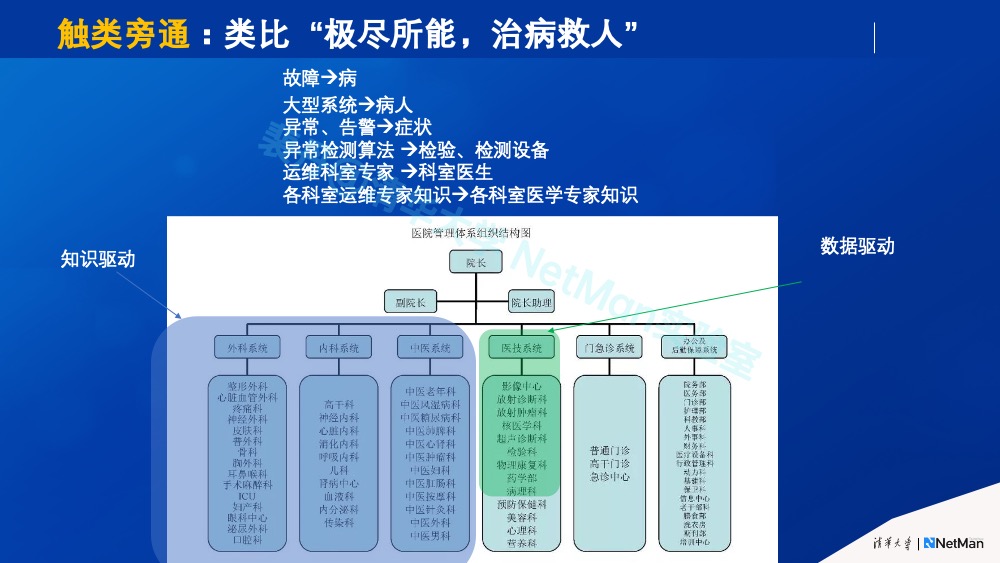
从科学技术的应用角度来说,AIOps也是大势所趋。我在从美国海归加入清华之前,曾短暂做过一段智能医疗,因此我个人习惯在思考AIOps时,从医学领域寻找灵感和启发,也就是“触类旁通”。这个习惯也深受我博士导师加州大学洛杉矶分校张丽霞教授的影响,她曾多次公开建议从生物学中寻找互联网架构设计的灵感。的确,很多时候“太阳底下没有新鲜事”,在运维领域遇到的很多问题,在其它科学领域都可能遇到过,而“它山之石可以攻玉”。
在此我简单分享下运维与医学的类比,希望在思考方式方面给大家一些启发。我们可以把负责排障的数据中心组织及员工类比为医院及员工,故障类比为疾病,数据中心软硬件系统类比为病人,异常和告警类比为症状,异常检测算法类比为检验、检测设备,运维科室专家类比为医院科室医生,各科室运维专家知识类比为各科室医学专家知识。简单疾病(故障)单独科室就能处理了,复杂病症(故障)需要关联各种数据,并且跨科室专家会诊。
做完以上类比,你会发现,其实现代医学领域一直在践行AI 3.0里的“知识驱动+数据驱动”,各种新的检验检测技术层出不穷,医学诊断知识也在不断地提升,两者的结合促进了医学领域的高速发展。(后续其它原则还会更多使用这个类比)。
上述以医学为例,阐述了科学技术应用角度的大势所趋是知识、数据融合,希望能让运维人员更坚定地践行AIOps。
原则2 (价值路线):统筹规划、要事优先、点面结合
智能运维已经如火如荼发展了一段时间,很多企业都在做AIOps的筹划,但是先做什么后做什么?Big Picture是什么?如何做多年规划的同时又逐年有实质落地效果?下面我将基本抛开技术实现的角度,仅从AIOps交付的价值角度,谈一下规划的三个原则。
原则2.a 统筹规划
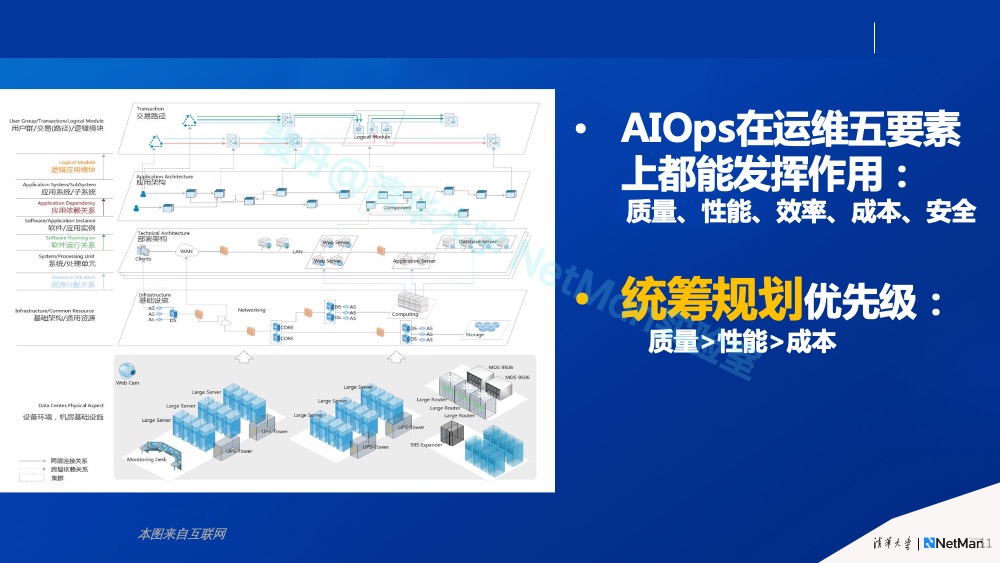
首先,AIOps在运维的五个基本要素(即质量、性能、效率、成本、安全)中都有很好的应用前景。统筹规划的优先级方面,效率(Develop)相对独立,安全也相对独立,那么剩下的质量、性能和成本,先关注哪个?根据以往的经验,还是要先关注质量,即系统可用性,然后是性能,在这个基础上再进行优化成本。本文后续都聚焦在运维质量上进行讨论,而在性能和成本上的落地原则大同小异。
这里类比一下医学里著名的扁鹊三兄弟(下图),对于目前常出故障的一个系统来说, 我们最需要像扁鹊那样治大病的医术,其次需要像扁鹊二哥那样治小病的医术,最后需要像扁鹊大哥那样治未病的医术。具体而言:我们首先要降低故障修复时间,这是规划里最重要、最痛的点;其次,我们要做延长无故障时间,识别并消除那些小隐患;最后,我们还要通过故障演练,即便日常中没有小故障发生,但通过注入故障引出问题,然后解决掉问题,不影响真正的用户。

规划中最迫切的“运维质量:降低故障修复时间”有很多细分步骤,实际落地起来挑战重重:多源多模态且信噪比低的运维数据;关联所需要用到的依赖数据非常复杂且不易获得,有时数据质量也不高。很显然我们无法一蹴而就,必须要统筹规划,分步骤、分阶段地实施,不断取得阶段性的成果。

统筹规划的前提是要总结出一个相对完整的体系,运维质量的体系包含四个维度:一家企业所属行业;一家企业有哪些运维对象(如中间件、数据库、存储、应用等);有哪些不同的故障类型及在数据中如何体现;采用的是哪些技术架构(如集中式架构、开放架构)。统筹规划的实施就是在多维度组合中确定哪些先做、哪些后做。
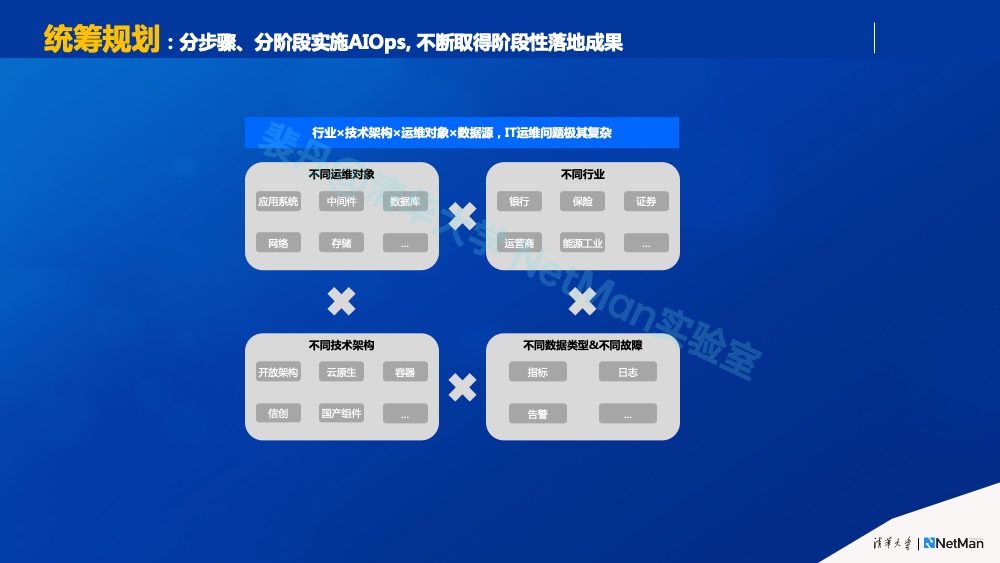
原则2.b 要事优先
在上述体系中,决定先做的原则是要事优先,即聚焦并串连最终导致业务故障的常见异常。这里引用一个数字,某企业80%的业务故障是由少数组件的少数类型的故障导致的。这其实遵循了“二八定律“,20%的组件故障类型导致了80%的业务故障。因此,我们应首先聚焦解决这些常见故障,要有全局视野,先抓重点细节,聚焦并串起导致那些业务故障的常见组件故障,这就是规划AIOps时从价值角度出发的“要事优先”原则。
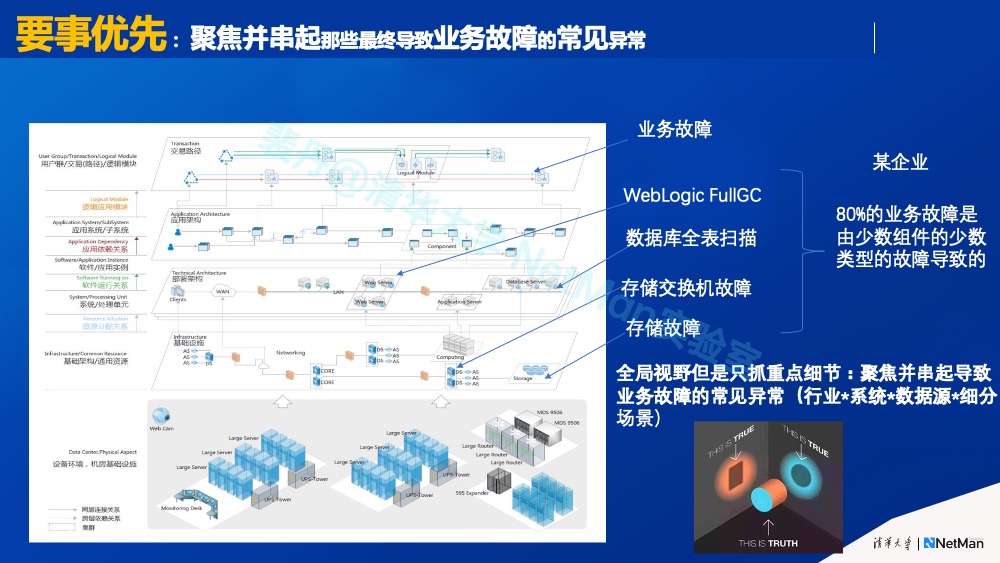
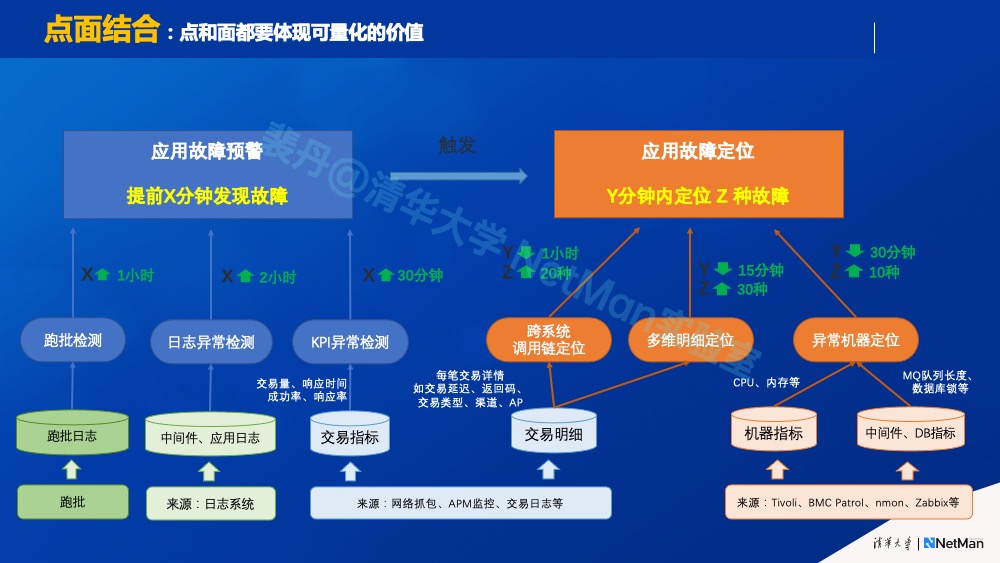
原则2.c点面结合
规划落地AIOps时,有两种误区:一是只看有可量化价值的具体的技术“点”(如业务指标异常检测);二是只看有可量化的端对端价值的场景(“面”,如MTTR)。而我们总结的原则是“点面结合”。比如,也许因为依赖其它技术点, 业务指标异常检测还没有产生端对端的效果(降低MTTR),但是其本身有一些评估指标(相比传统方法提前X分钟发现故障),这能给予我们很大的希望。就像医院里一个医疗设备,它比原来的设备检测得准、检测得快,它的价值就应该得到认可,它的价值不能因为需要一些其它技术点才能产生完整的端对端价值而被否认。反之,对于端对端价值的不懈追求并且以量化方式不断衡量(如MTTR),能清晰指引我们规划需要不断突破的技术点。因此,规划时,点和面都重要,点面要结合,都要体现可量化的价值。
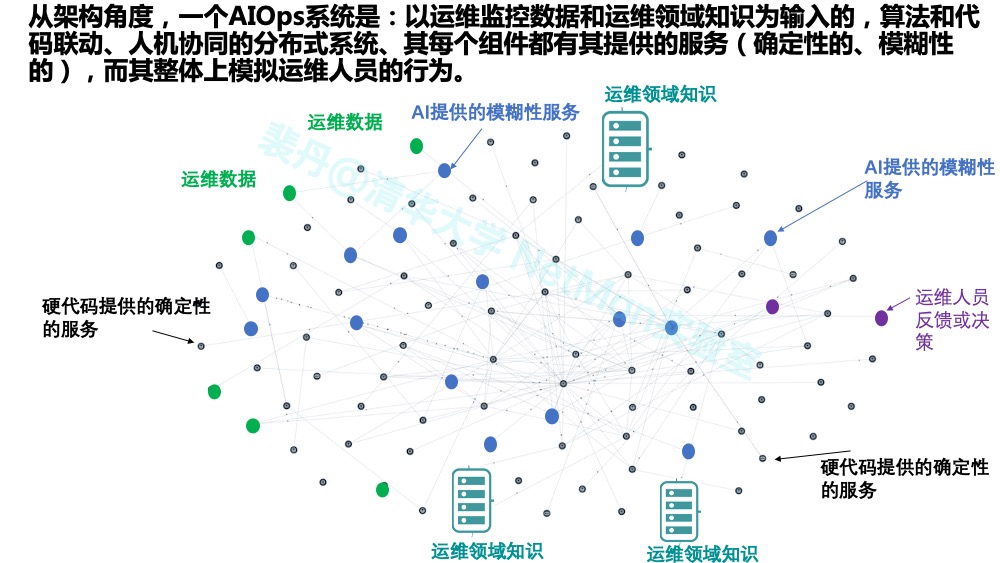
原则3 (架构路线):数(据)知(识)驱动、算(法)(代)码联动、人机协同
前述原则2讲的是从价值角度如何做AIOps规划,而原则3则聚焦AIOps在架构上的路线。总体而言,从架构角度(如下图所示),一个AIOps系统是:以运维监控数据和运维领域知识为输入的、算法和代码联动的、人机协同的分布式系统、其每个组件都有其提供的服务(确定性的或模糊性的),而其整体上模拟运维人员的行为。下面我们分三个方面逐一阐述。
原则3.a数(据)知(识)驱动
数据和知识双轮驱动的要点在应急排障中的具体体现:一是基于全量数据做异常发现;二是基于知识对一个个零散的异常信号进行关联,从而获得“上帝视角”(如下图)。

具体而言,在运维排障中的“上帝视角”类似下图所示,每个节点是系统运转过程中的一种可能异常(对应的是一个数据源和异常检测算法)。这些异常在系统里的传播关系就是图中的“边”,最终形成这样的一幅运维排障的知识图谱。其核心思路是:① 基于所有可用监控数据的异常检测(寻找所有可能异常);② 基于异常传播的故障定位(将所有相关异常中按照根因可能性排序)。
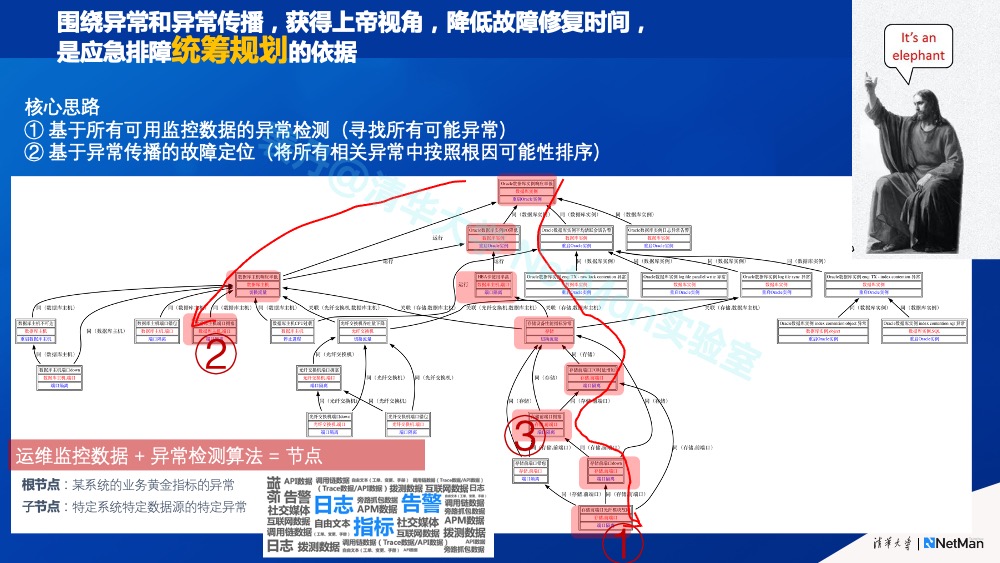
我们会发现,之前提过的原本并列在一起的各种异常检测算法(如下图),现在通过这张图把它们连在一起,所有的运维排障工作通过这个图实现了。
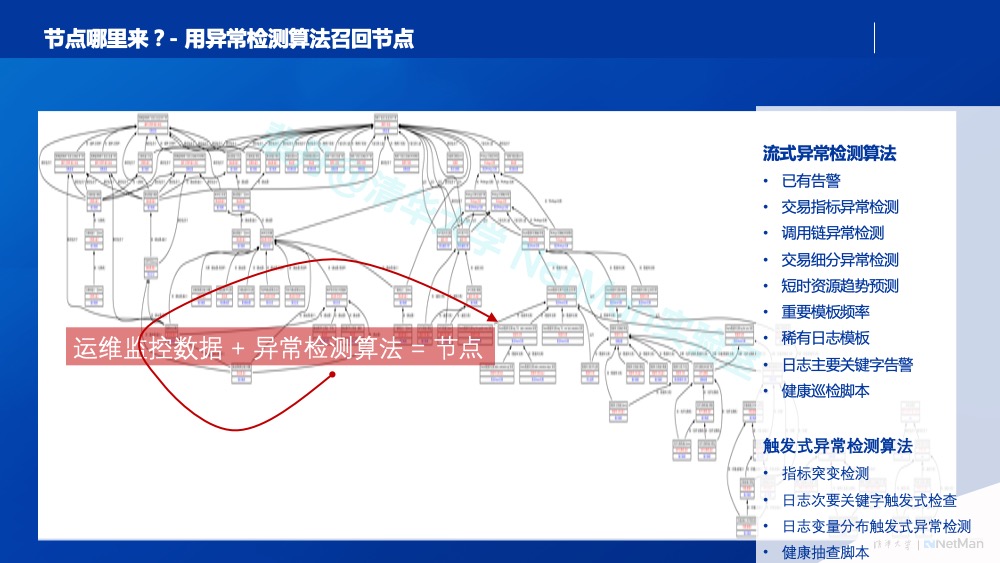
图的“边”来自于依赖关系知识(逻辑组件之间的调用关系图、逻辑组件在物理组件上部署关系图、物理组件的网络路径关系图)和专家知识(组件内运维故障间的因果关系图, 手工配置或算法挖掘)。
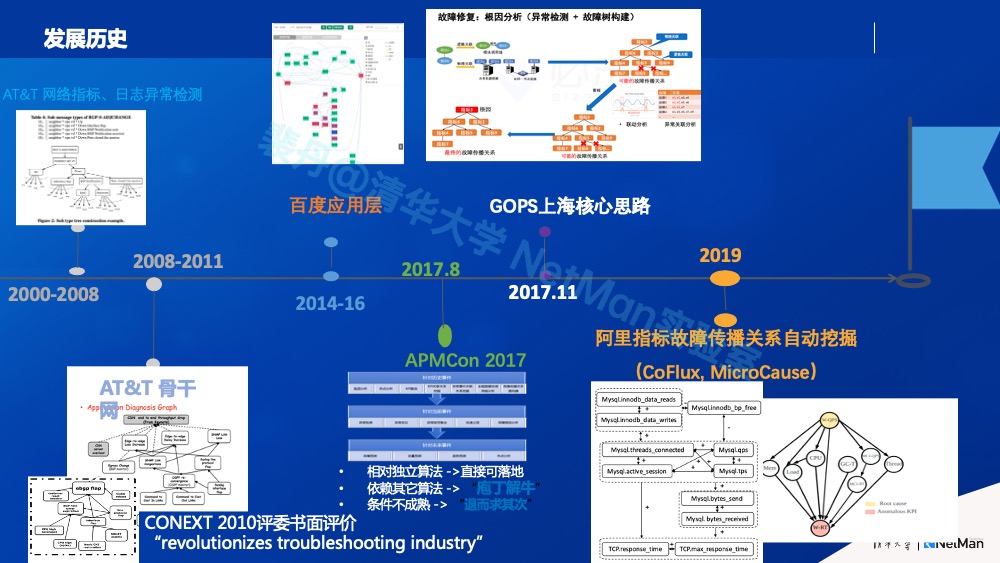
以上“数据知识双轮驱动”的框架,我们在2009年在运营商骨干网运维成功落地之后的十几年间,攻克了领域迁移、算法升级、挖掘替代人工配置等挑战(如下图),目前已经具备了IT运维领域推广的条件。
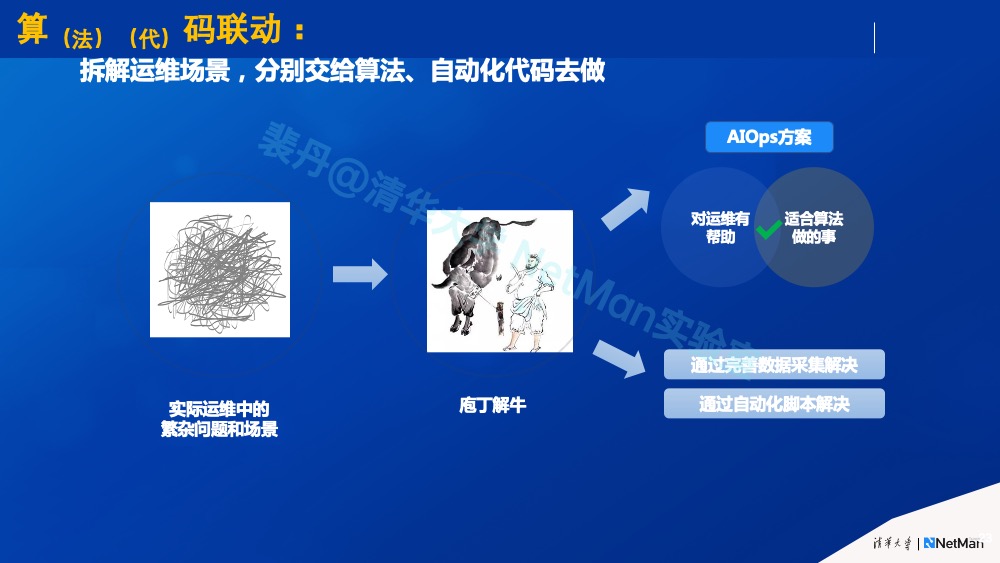
原则3. b: 算(法)(代)码联动
如原则1.b所述,AI应用里不仅包含算法,还可能包含一些(流程、规则)自动化代码。对于一个纷繁复杂的运维场景,我们的任务是通过庖丁解牛的方式,分解成哪些是可以通过算法做的事情、哪些是可以通过自动化脚本做的事情(比如在排障的时候,通过一个SQL获取数据库的一个监控指标)。AIOps系统是一个大型分布式软件,目标是应急排障,不同组件之间相互配合,构成前述原则3那幅图所示的分布式系统。具体的一个组件的实现方法可以是确定性逻辑的硬代码还是模糊性逻辑的基于机器学习方法,就如同一个构成在线软件服务的不同微服务内部用哪种语言实现都可以。
原则3.c:人机协同
前述原则3那幅图所示的分布式系统中包含了一个重要部分,即运维人员的反馈和决策。也就是说,AIOps架构是一个人机协同的架构。这是为什么呢?
我们在实践的过程中发现,AIOps与一些常见的人工智能领域(如计算机视觉)有一个非常显著的不同,即运维数据没法采用众包的方式交给一个普通人来进行标注,必须依赖运维专家,但是运维专家可能没时间或者不愿意标注。
因此,在算法选择时的优先级顺序是:1. 无监督算法;2. 无监督算法 + 主动学习;3. 弱监督算法(如多实例学习,PU学习);4. 有监督算法 + 迁移学习;5.有监督学习。
但是无论采用有监督还是无监督算法,评估的时候都需要标注数据,这个就依赖于日常多积累案例,以及它周边的相关监控数据,从而能够评估无监督的算法。

本人认为,上述“无监督算法+主动学习”是一种有前景的方式,属于“人机协同”(如下图中的例子)。我们在 Infocom 2020有一个安全相关的工作,就是human in the loop--- 无监督异常检测+人工在线反馈,能够检测零日攻击。发生零日攻击时,其攻击指纹尚未发现或部署在防火墙中,因此用传统基于指纹的检测方法通常会漏掉零日攻击。无监督方法能够检测出来零日攻击的反常流量,不过不能保证清晰地区分所有攻击和所有新上线的应用的模式,所以我们用线上人工反馈的方式进行反馈。这里要注意的是,这些反馈是该在线系统运行的有机组成,用户在使用工具时的常规步骤(而不是标注离线数据),其使用过程本身就给系统提供了反馈。我们在若干其它工作中也发现把 “人机协同”作为AIOps架构的一部分是行之有效的。
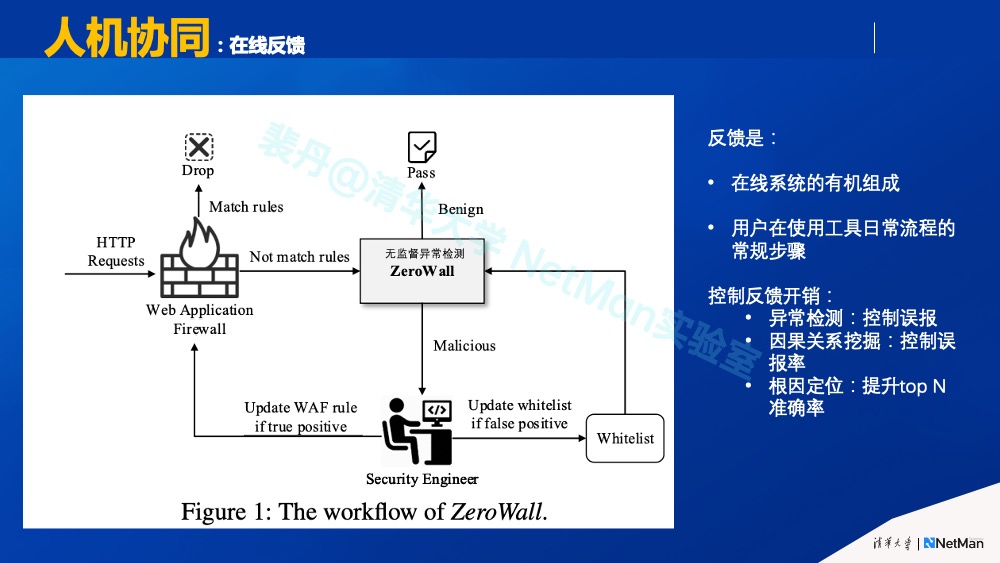
原则4 (算法路线):持续迭代、细分融合、精准建模
原则3 中讲到的AIOps技术架构中包含基于机器学习算法组件,而这些组件的落地过程不同于那些基于硬逻辑的代码开发。因此原则4总结了基于机器学习的算法组件的三个落地原则:持续迭代、细分融合、精准建模。
原则4.a 持续迭代
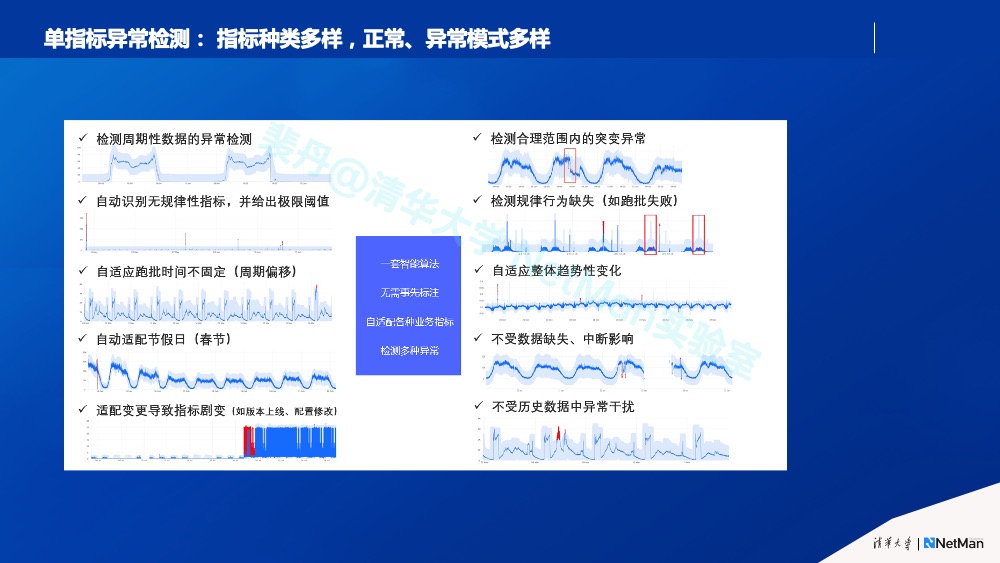
给定一个机器学习算法及超参,其算法效果主要取决于其数据质量;给定一个数据集合,其算法效果主要取决于具体用什么机器学习算法及超参。以AIOps领域研究最深入的单指标异常检测为例,运维指标种类非常多,比如说业务指标、机器指标、网络指标、数据库指标等;同时正常、异常模式也非常多(如下图所示)。这就导致在一类指标(比如业务指标)上效果良好的算法,在应用到一个另一类指标(比如机器指标)时效果就会变差,这时往往会要求对原有算法迭代更新,有时只是超参发生变化,但是很多时候需要研制新的算法。
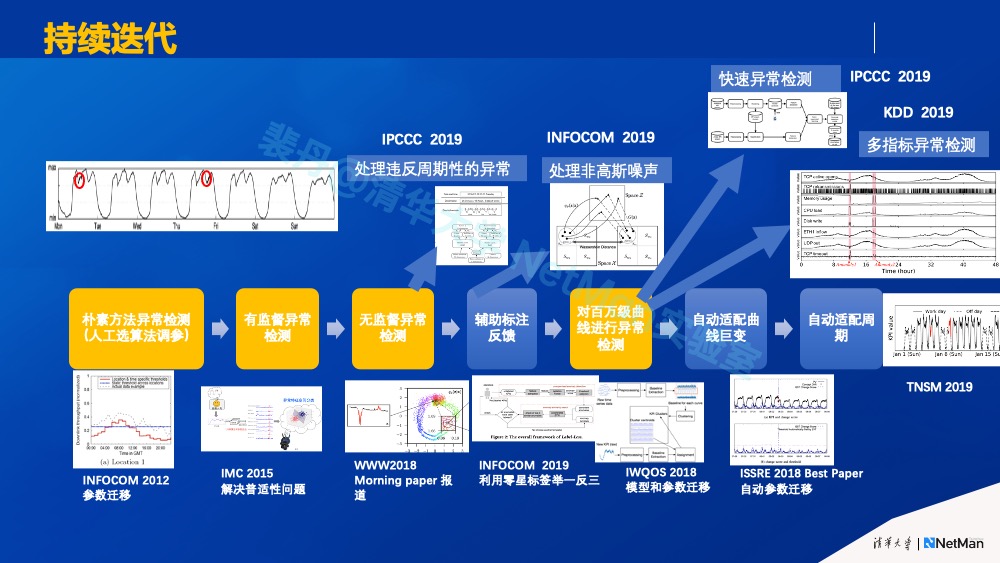
比如我们和阿里联合研制的的Donut算法(WWW 2018)在阿里平滑业务曲线上效果不错,但是在阿里数据库主机的剧烈波动的机器指标上试用后发现效果不佳,于是我们就迭代出更适合的Buzz算法(INFOCOM 2019), 见下图。我们在逐渐攻克指标异常检测的过程中,此类例子不胜枚举。我们持续迭代(研制、上线、测试、更新、上线、测试,…)指标异常检测在各类场景的算法,逐渐解决了模型泛化问题、结果可解释性问题、模式巨变适配问题、训练开销问题。这与《实践论》及《原则》非常类似,“实践、认知,再实践、再认知,循环往复一直无穷,最后把实际问题解决掉。”由于特定机器学习算法在特定数据集上的效果的不确定性,我们认为AIOps算法落地必须持续迭代。
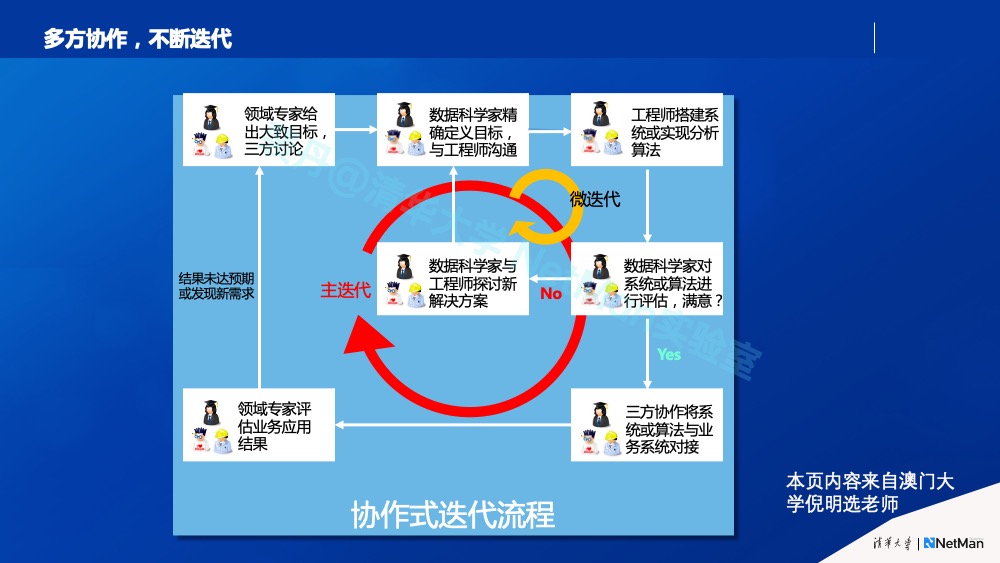
澳门大学校长倪明选教授也曾总结过“数据分析的协作式迭代流程”(如下图):数据分析,需要领域专家、工程师、算法专家讨论目标,进行大循环的迭代,然后算法和工程师进行微迭代,大小循环都要往复很多圈,才能实际落地解决一个现实中的复杂数据分析问题。
原则4.b 细分融合
原则4.a 中提到AIOps落地过程中,从研发的角度讲,一个细分场景只要有实际意义,我们就应该跟它死磕,最终把它解决掉。假设我们有一组算法(比如单指标异常检测),其中每个算法能应对一个单指标异常检测场景;但是在实际部署运行这组算法的时候,我们不能指望靠算法专家在现场判断一个实际场景应该匹配哪个已实现的算法,而是希望有个“融合“算法自动根据现实数据匹配对应算法。也就是“场景要先细分,再融合成一个大的场景”。
以单指标异常检测为例,我们自动对它进行画像,然后通过领域知识知道每一种画像适合哪种算法。最终通过这种方式,知识、画像、知识映射到具体的算法和算法的组合,达到了融合的效果。(据我所知,很多计算机视觉的应用也是采用了多个算法的集成融合。) 因此,我们研制算法的时候要细分,逐个进行原理突破,落地突破之后再集成融合,这也是AIOps落地实践中一个非常好的经验。
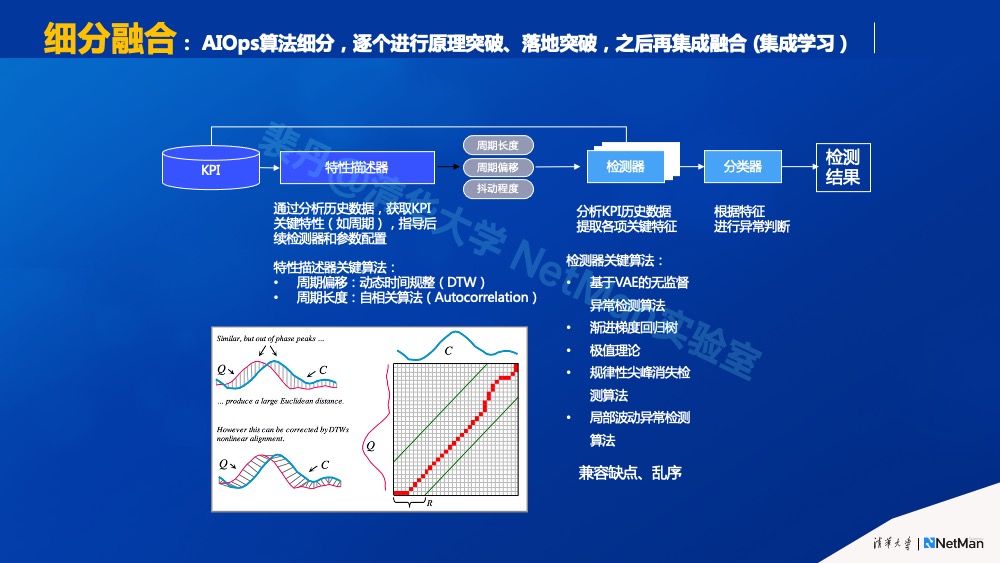
原则4.c 精准建模
在科研领域,一个问题的建模不同,解决方法就可能不一样。下面以在AIOps领域中的难题——根因定位为例:在业务故障发生的时候判断到底是哪个节点出的什么问题导致了业务故障。早些年,我经常被问到的一个问题,“我没有那么多故障数据,故障分类之后每类的数据更是少之又少,那我怎么用机器学习训练根因分类算法呢?”这个问题的问法已经假设了根因定位问题是个有监督分类问题。如果把根因定位问题建模为有监督分类问题,这个问题的确非常难解决,因为前面原则3.c中已经强调大量标注是很难获得的。但是为什么一定要建模成有监督分类呢?为什么不能建模成像搜索引擎那样的推荐问题呢?比如推荐出前五名的可能根因,让运维人员去点击交互,选出他认为的最可能的根因,而他们的选择作为系统在线运行中获得的标注,进行前述原则3.c中的人机协同,就不需要大量的故障及标注了。换个思路,豁然开朗。
再举一个例子,面对海量的机器指标,我们是选择资源消耗较多的流式异常检测,还是选择采用资源消耗较少的触发式异常检测(由外部条件触发)?流式异常检测和触发式异常检测的算法原理上可能就有很大的不同。
通过以上的例子,我们想说明一点:对于一个具体的问题要精准建模才可能把它解决好。我们经常说“做科研,只要定义好了问题定义,就相当于已经完成了一半。”基于对运维场景及算法特性的深刻理解,对算法问题精准建模,是AIOps算法落地的重要原则。

原则5:标准引领、治(理)(应)并进、生态合作
虽然AIOps势在必行,但是其落地时面临众多挑战,其中非常重要的一条就是“生态挑战”。生态中涉及到的不同单位、运维人员、运维专家、运维负责人、产品经理、软件工程师、算法工程师、算法科学家、交付工程师、项目经理、高校科研人员,对AIOps的认知、能力、诉求、优先级、数据质量等等都不尽相同。为了避免“表面上红红火火,实际上一盘散沙”的陷阱,我们提出“标准引领,数据治理和AIOps应用齐头并进、生态合作”的三个原则。
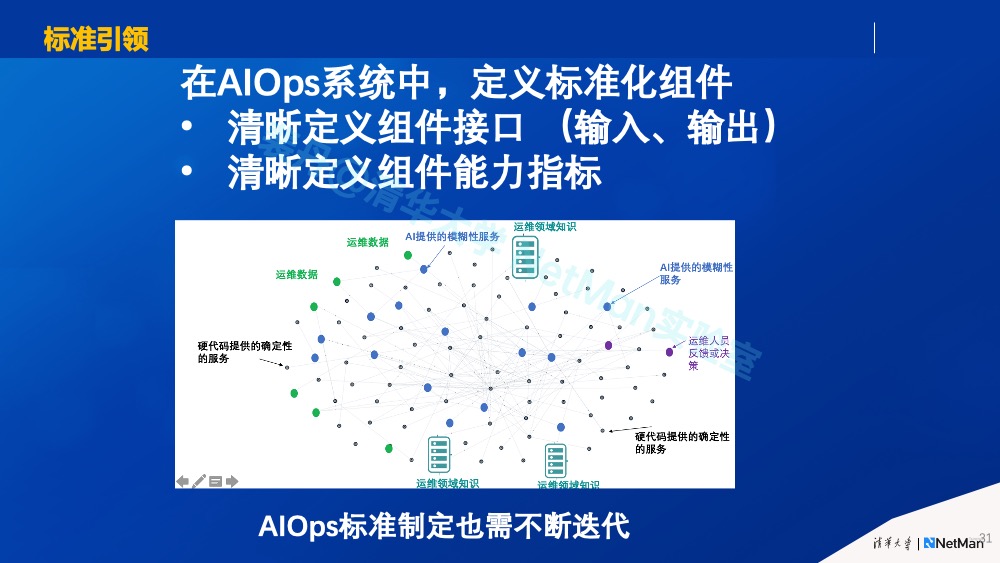
原则5.a 标准引领
建立标准是在生态相关各方建立共同语言、步调一致的最可行手段,也是一个生态系统健康、繁荣、可持续发展的前提。参见互联网标准(RFC)和移动通讯网络标准(3G,4G,5G)分别在互联网和移动通讯网络蓬勃发展过程中的核心引领作用。
我觉得前述原则3中的 AIOps系统架构可以作为AIOps标准化的一个依据。具体思路是:针对常见组件(比如业务指标异常检测),把它作为一个软件服务来看待, 清晰定义其:1)输入格式要求、采样间隔要求、质量要求;2)输出格式及质量要求;3)组件能力指标(如误报率、漏报率、检测延迟等)。同时定义组件之间的关系,比如异常检测结果输出给根因定位模块。
当然AIOps还在快速发展中,因此标准制定也一定无法一蹴而就,而是必须持续迭代,不断地引领生态各方在认知上取得共识、在产品上实现互通互联(参见原则5.c 生态合作)。
原则5.b 数据治理和AIOps应用齐头并进
数据质量在AIOps落地效果的重要性毋庸置疑。但是数据治理和AIOps应用孰先孰后呢?这一点其实是比较有争议的。一种观点是“要先做好数据治理,才可能做AIOps落地”。听起来很有道理。的确,数据不行怎么出效果呢?但是,根据我20余年AIOps落地经验,我旗帜鲜明地反对 “先泛泛做数据治理,再AIOps落地”的做法。大家可以看一下下图中我微信朋友圈的讨论,其中的一个精华留言是 “脱离实际业务场景来做数据治理和脱离了应用架构来做数据治理,完全是镜花水月”, 我深表赞同。
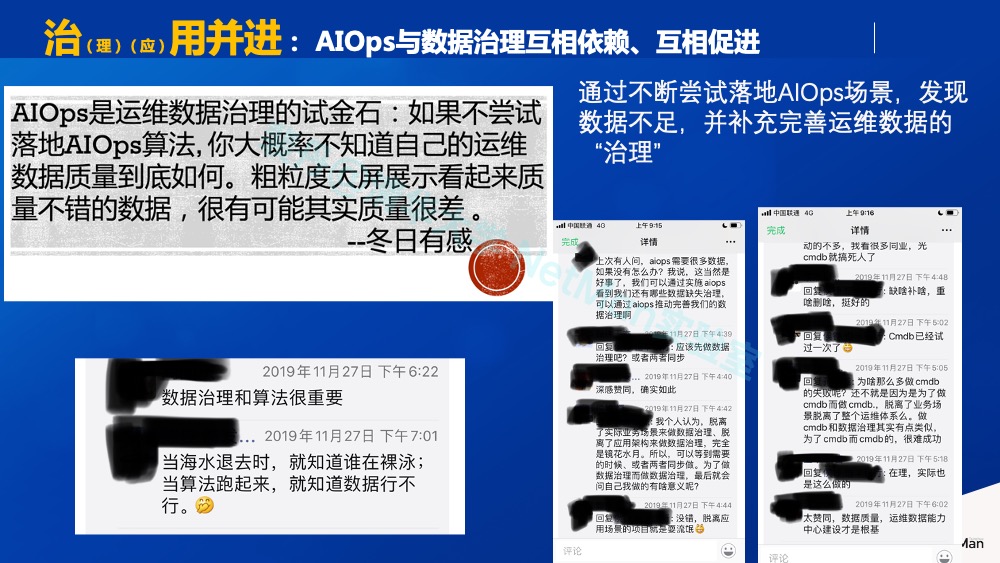
反过来说,我们提倡不断尝试落地AIOps具体场景,发现对应的场景所需的数据不足,这个会给数据治理提供针对性的指导,而不是盲目的治理。我举两个例子。
在第一个例子中,我们最近一个根因定位项目频繁使用CMDB数据,发现了该CMDB数据源的很多非常具体的不准确的地方,而这些不准确的地方在该CMDB数据源自反而泛泛的数据治理中都没有被识别出来(不知道自己不准)。这个例子表明“先泛泛做数据治理,再AIOps落地”反而可能做不好数据治理。
在第二个例子(见下图),我们列举了一些之前落地实践中总结出来的具体场景(如业务指标异常检测、机器指标异常定位)中各自的数据质量要求。如果说达到了这个要求,就可以保证出效果,如果达不到这个要求,效果就会打折扣。这个怎么来的呢?一定是在实践中总结出来的,而不是泛泛地依赖数据治理得来的。当然这些已经总结出来的在特定场景下的数据质量要求可以用于指导一家新机构在进行AIOps落地这些特定场景前的数据治理。

所以,我们说数据治理和AIOps应用是齐头并进的,是互相依赖、互相促进的,不是说一定谁前谁后。泛泛而谈 “先做数据治理,再AIOps落地”是不可取的。针对具体场景,如果已经有前人总结出来的、甚至已经标准化的数据质量标准(如指标的采集间隔和连续性),当然可以先尝试实施相应治理,再落地算法;对于像CMDB那类的准确性需要上层应用(比如根因定位)的反馈才能有针对性地治理的数据,则要治理与应用齐头并进。
原则5.c 生态合作
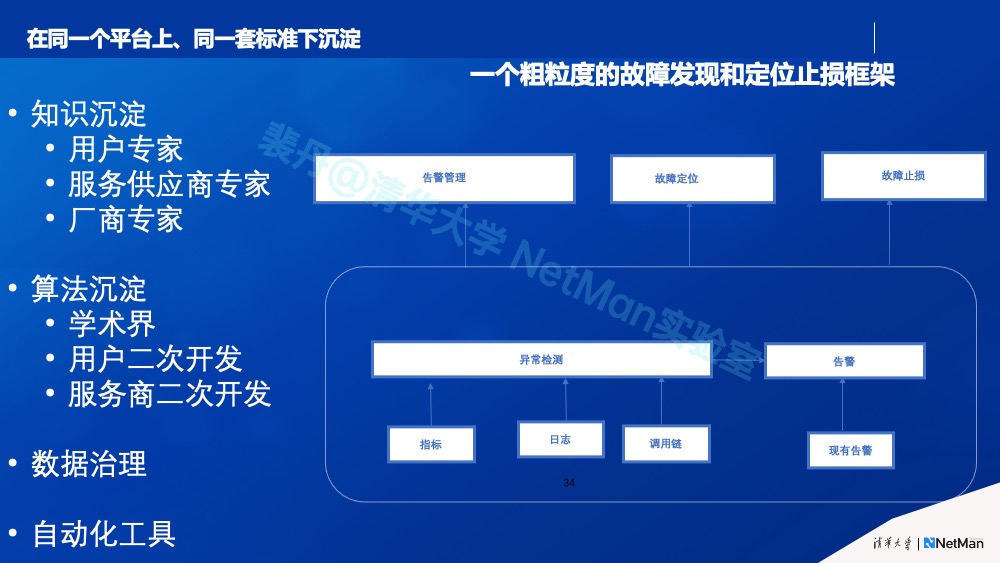
最终我们希望,在同一套智能运维标准引领下,在一个由标准构建起来的大“平台”上(参见移动通讯网络中的4G,5G标准构建其的大“平台”),生态各方进行知识沉淀(用户专家的知识、服务供应商专家的知识、厂商的专家的知识)、算法及代码的沉淀(学术界、厂商、用二次开发、服务商二次开发)、以及数据治理标准的沉淀、服务化组件的沉淀,以及AIOps相关的自动化工具的沉淀,在遵循生态共同制定的标准的前提下,实现高效互通互联,指数级加速AIOps落地。
最后我总结一下AIOps落地的五大原则:
大势所趋: 顺势而为、知己(Ops)知彼(AI)、触类旁通
价值路线: 统筹规划、要事优先、点面结合
架构路线: 数(据)知(识)驱动、算(法)(代)码联动、人机协同
算法路线: 持续迭代、细分融合、精准建模
生态路线: 标准引领、治(理)(应)用并进、生态合作
希望本文对中国AIOps落地起到绵薄之力,也希望所有关心AIOps的同仁能齐心协力,共同建立AIOps的良好生态!