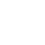2021国际AIOps挑战赛季军平安科技团队方案介绍
发布时间:2021-09-28 16:47:58
团队介绍
参赛团队pa_tech由平安科技运营工具平台团队、混合增强算法团队构成,负责平安集团的AIOps建设,以全链路监控和业务数据为基础,以大数据分析处理和机器学习算法等技术为支撑,为现有运维管理工具和管理体系赋予统一数据管控能力和智能化数据分析能力,全面提升运维管理效率。目前平安集团AIOps已实现异常检测、根因分析、智能预测等三大场景的数据平台和AI模型建设和落地。
赛题分析
此次赛题属于比较典型的运维场景根因分析,线上模型会从Kafka实时接收各维度的监控数据,再通过算法进行实时分析,并上报故障的根因。
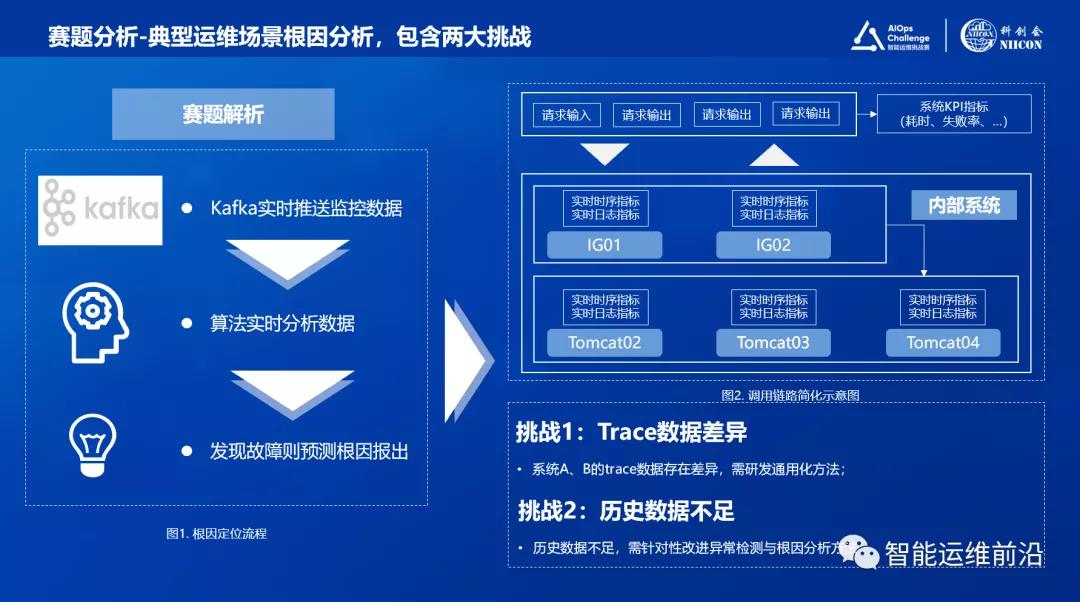
图1:赛题解析及调用链简化示意
此次竞赛推送的数据方面分为四个维度,分别是metric时序数据、metric日志数据、KPI时序数据、trace调用链数据。其核心难点存在2个:
- 系统A、B的trace数据存在差异,需研发通用化方法;
- 历史数据不足,需针对性改进异常检测与根因分析方法。
方案介绍
对于此次赛题,平安科技团队的根因分析方案主要由三步骤构成,分别是异常检测、故障触发、根因分析。

图2:根因分析算法流程
1、异常检测
1.1异常检测难点分析
异常检测算法在此次竞赛的难点在于,固定超参数的标准化异常检测模型(各指标用的模型和超参数相同),无法通用适配各种特性的指标。例如对于以下的CPU使用率指标,只有极大的增幅才可能成为故障原因,因此需要设置敏感度较低的参数,固定的参数设定会产生大量误告(在其他场景指标下也可能产生漏告)。
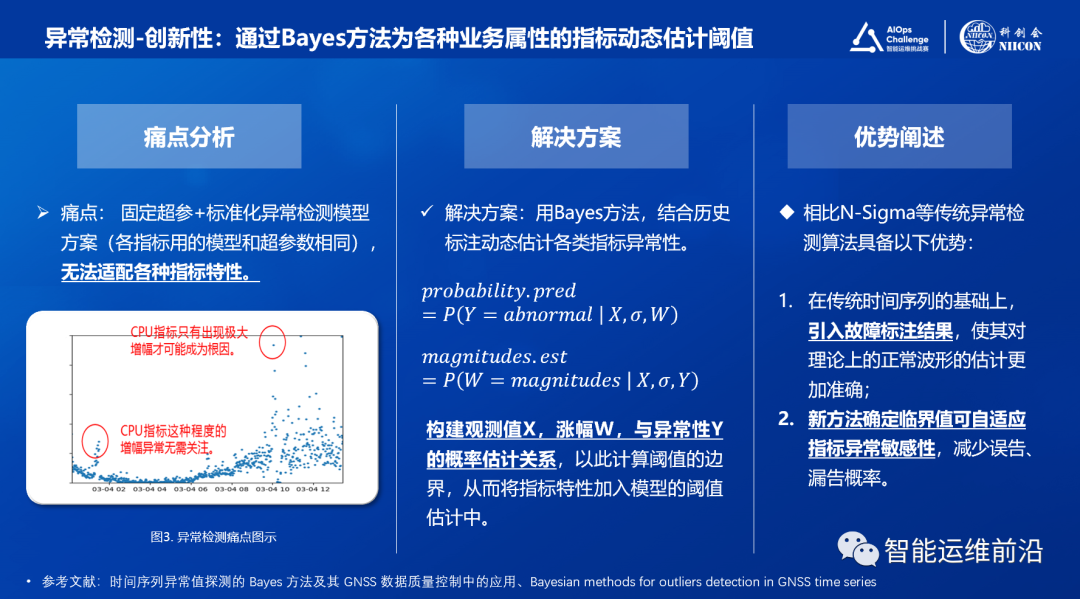
图3:异常检测难点及解决方案图示
采用Bayes方法,可以将采集值特征与异常标注建立起关联,估算异常情况下各特征的概率密度以获得阈值边界,从而将指标特性加入模型的阈值估计中。
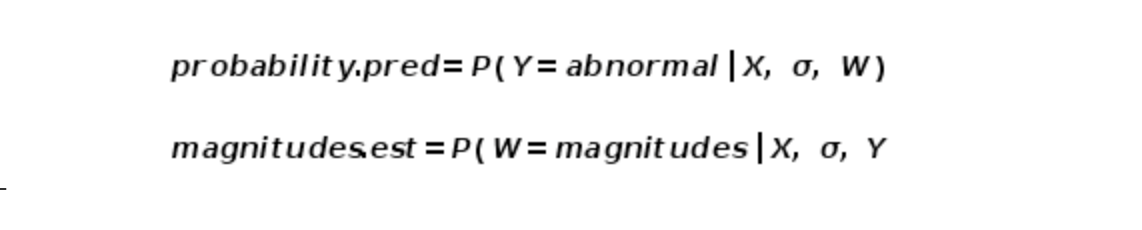
根据构建观测值X,涨幅W,与异常性Y的概率估计关系,以此计算阈值的边界,从而将指标特性加入模型的阈值估计中。
相比传统异常检测算法N-Sigma等,Bayes方法的优势主要表现在:
- 在传统时间序列的基础上引入故障标注结果,使其对理论上的正常波形的估计更加准确;
- 新方法确定临界值可自适应指标异常敏感性,减少误告、漏告概率。
1.2异常检测最终方案
基于Bayes方法,设计以下通用模型,能够泛化至各种数据场景。首先,对于某一实时采集值,取该采集值前5min或10min的采集值,结合Bayes方法对当前时刻进行动态阈值估计,从而完成异常性判定。其次,如果能够利用历史长期数据,就可以应用S-H-ESD等算法进行额外阈值估计,通过历史信息进一步提高精度。平安科技公司内部生产系统中的异常检测方案会参考历史2周数据从而进一步提高精度。
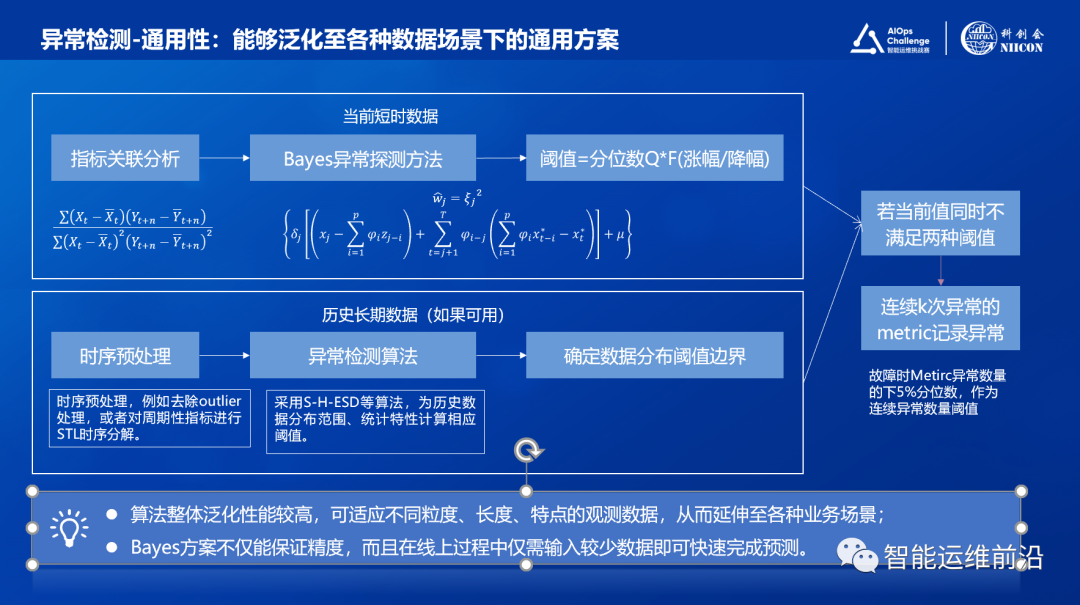
基于Bayes方法,设计以下通用模型,能够泛化至各种数据场景。首先,对于某一实时采集值,取该采集值前5min或10min的采集值,结合Bayes方法对当前时刻进行动态阈值估计,从而完成异常性判定。其次,如果能够利用历史长期数据,就可以应用S-H-ESD等算法进行额外阈值估计,通过历史信息进一步提高精度。平安科技公司内部生产系统中的异常检测方案会参考历史2周数据从而进一步提高精度。
图4:异常检测最终方案
异常检测方案的优势可以总结如下:
- 算法整体泛化性能较高,可适应不同粒度、长度、特点的数据,延伸至各种业务场景;
- Bayes方案不仅能保证精度,而且在线上过程中仅需输入较少数据即可快速完成预测。
2、故障触发
2.1数据缓存
为了随时触发故障的根因分析,我们需要将相关数据缓存,包括时序异常检测结果、日志异常检测结果、KPI时序值、trace调用链数据。
表1:缓存数据说明
2.1数据缓存
为了随时触发故障的根因分析,我们需要将相关数据缓存,包括时序异常检测结果、日志异常检测结果、KPI时序值、trace调用链数据。
表1:缓存数据说明
| 缓存数据 | 说明 |
| metric异常检测结果 | 各metric时间序列异常检测的告警记录,即若干告警的cmdb组件及其metric。 |
| 日志异常检测结果 | 日志分析异常检测的告警记录(统计关键词频次转化为时序进行检测),包含异常cmdb组件与指标。 |
| KPI时序值 | 系统服务KPI时序值,用于触发根因分析条件(后续弃用)。 |
| trace调用链数据 | 由Kafka推送的每一trace数据,当trace耗时高于预设值(低于该值则没有分析的必要)则将其缓存。 |
数据将缓存在预先建立的Detector类中,准备随时触发根因分析,并定时将无用的历史数据删除。
2.2故障触发
以下图4月26日KPI时序为例,4个标注故障中,只有第1个故障能够从KPI层面反映,如果以KPI作为唯一触发机制肯定会遗漏很多故障。
因此,对于故障的触发,方案将直接分析缓存的各维度数据判定故障与根因,而不会以KPI作为唯一触发机制。具体方法是,对缓存数据进行滑窗切片(以2.5min为步长,5min为窗口滑窗),对每个切片进行一次故障判定与根因分析,保证了在竞赛场景下较高的故障发现能力。
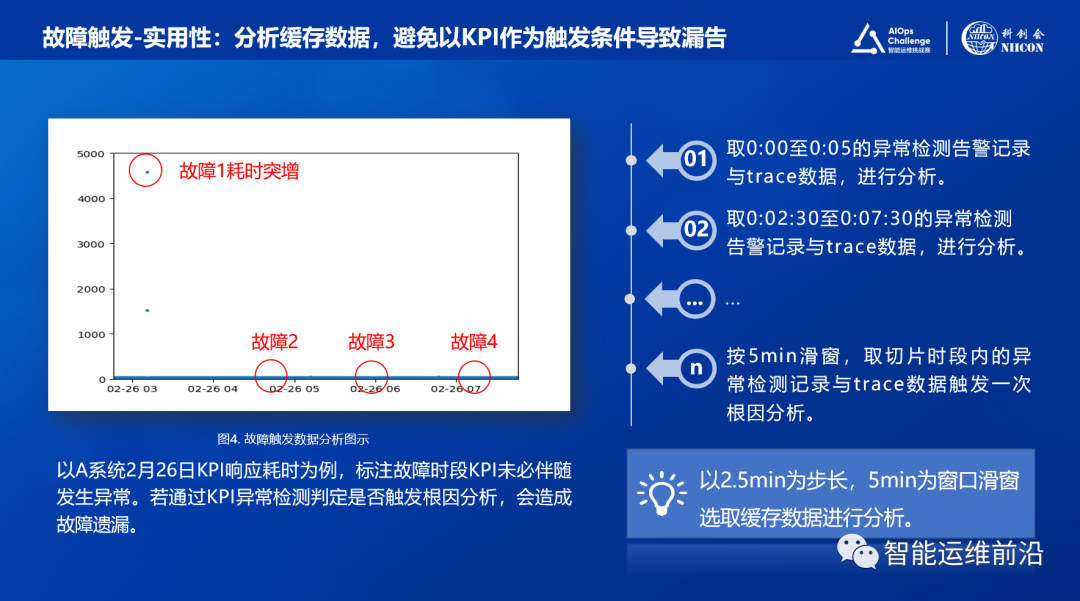
2.2故障触发
以下图4月26日KPI时序为例,4个标注故障中,只有第1个故障能够从KPI层面反映,如果以KPI作为唯一触发机制肯定会遗漏很多故障。
因此,对于故障的触发,方案将直接分析缓存的各维度数据判定故障与根因,而不会以KPI作为唯一触发机制。具体方法是,对缓存数据进行滑窗切片(以2.5min为步长,5min为窗口滑窗),对每个切片进行一次故障判定与根因分析,保证了在竞赛场景下较高的故障发现能力。
图5:滑窗分析示意
3、根因分析
3.1前期思路
在前期思路中,参考了公司项目方案,步骤流程如下,
- 获取运维系统下各cmdb组件及其监控数据(指标时序数据与调用链数据);
- 构造特征工程(例如异常频次,trace执行耗时等);
- 通过监督学习模型(随机森林)为每个cmdb组件计算概率。
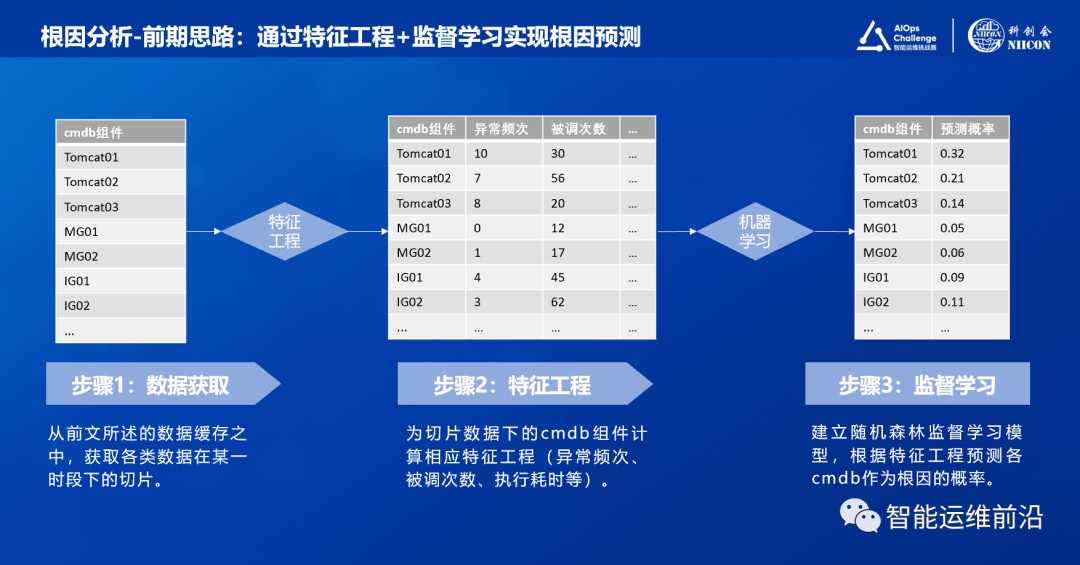
图6:根因分析前期思路示意
当前系统下,预测概率越高的cmdb组件作为根因的可能性越大,因此取最高概率的cmdb组件作为预测结果并输出上报。
3.2改进方案
上述思路在此次竞赛或者是一些现实商业场景中存在如下难点:
- 用户标注样本少,难以训练得到较优模型;
- 标注数据集中在一两天或某种类型,存在偶然性。
考虑到上述难点,方案尝试迁移项目训练模型特征信息,解决新场景下标注少的问题。具体流程如下:
利用项目训练得到的随机森林模型,提取模型的特征重要性作为特征权重;
利用项目训练得到的随机森林模型,提取模型的特征重要性作为特征权重;
- 在竞赛场景中,进行相同特征工程处理,并对所有特征进行归一化;
- 对归一化后的特征,按特征重要性进行加权求和,所得score即为根因预测分数。


图7:特征重要性示意
这套方案存在如下优势:
- 较小的启动成本,新场景提供少量标注样本即可适配;
- 商业场景中可更快完成上线部署,不断积累数据并迭代优化。
以B系统简化示意为例,介绍具体计算流程。在某一系统B的切片下,方案为系统B下所有cmdb进行特征工程与归一化,随后通过加权计算根因预测分数score。
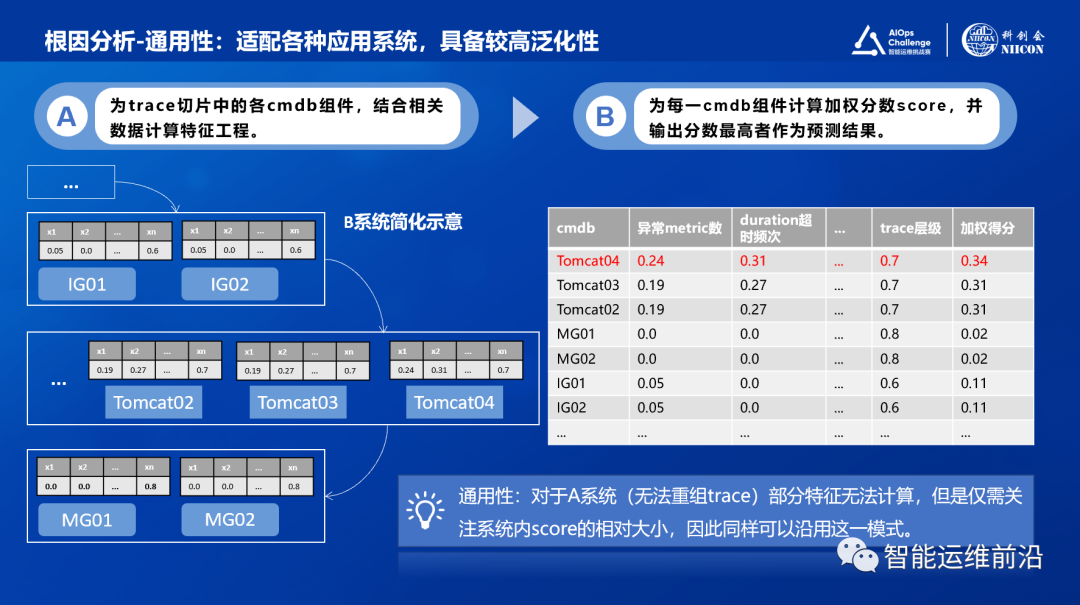
图8:B系统根因预测分数score计算示意
通过上述计算,可以确认Tomcat04得分最高作为候选,并通过score阈值确认当前切片有无故障,如有异常再将Tomcat04上报。因此通过这一方法,可以同时确定是否故障以及对应的根因。
关于通用性,对于A系统无法重组trace,部分特征无法计算。但是, 此方案仅需关注cmdb组件间的相对score比较,因此仍然可以沿用这套方案进行加权评分并找到最大值。因此,这套方案具备较高的通用性,可以通用适配不同数据可用性下的场景。
拓展空间
第一,可以摒弃现有“异常检测-根因分析”两步流程,避免误差传播,而是直接结合时序特征与trace特征联合建模并定位根因。
第二,对于异常检测方案,可以尝试VAE、LSTM等深度学习模型。此外,在数据支持前提下,也可引入历史数据参与阈值的估计,以提高模型精度。
第三,对于根因分析方案,根据公司内部项目经验标注的样本量若达到80以上,监督学习模型就能达到较理想的精度,因此也可以通过引入更多标注样本尝试监督学习模型的方向。
第二,对于异常检测方案,可以尝试VAE、LSTM等深度学习模型。此外,在数据支持前提下,也可引入历史数据参与阈值的估计,以提高模型精度。
第三,对于根因分析方案,根据公司内部项目经验标注的样本量若达到80以上,监督学习模型就能达到较理想的精度,因此也可以通过引入更多标注样本尝试监督学习模型的方向。