2021国际AIOps挑战赛季军"宝兰德"团队获奖方案分享|基于地震模型的根因探索
发布时间:2021-08-13 17:44:56
/ 团队介绍 /
本次参赛选手主要来自于宝兰德研发部智能运维团队。北京宝兰德软件股份有限公司成立于2008年,是一家专注于基础软件研发及推广的高新技术软件企业。宝兰德软件已经覆盖到了OpsLink智能运维、WebGate融合监控、DataLink大数据、BESWare基础中间件、CloudLink云计算等多个产品线。核心产品包含:OpsLink AIOps智能运维产品、WebGate性能监控产品、DataLink DI数据集成平台、BES Application Server应用服务器、CloudLink CMP容器管理平台等。
/ 方案介绍 /
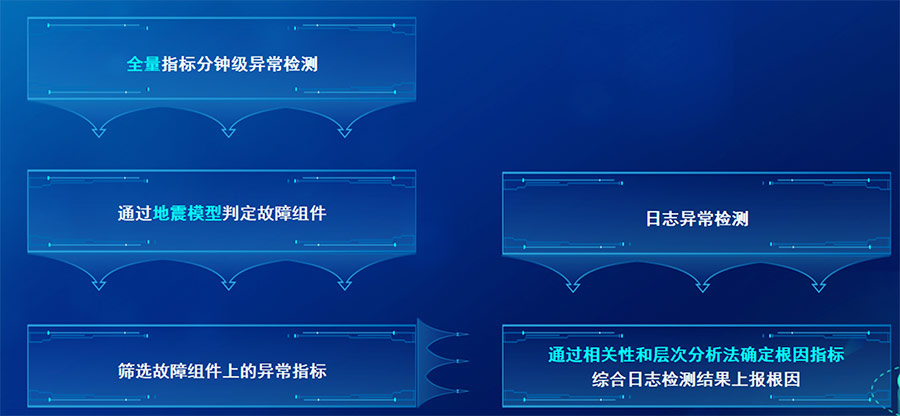
我们的方案分两条线并行开展,一条线是根据全量指标的异常检测结果,通过地震模型(之后的内容会详细介绍地震模型)判定出故障组件,再筛选出故障点上的异常指标,通过相关性和层次分析法的裁剪确定出根因指标,然后和另外一条线日志异常检测的结果合并,作为最终根因一并上报。
赛题难点及数据探索
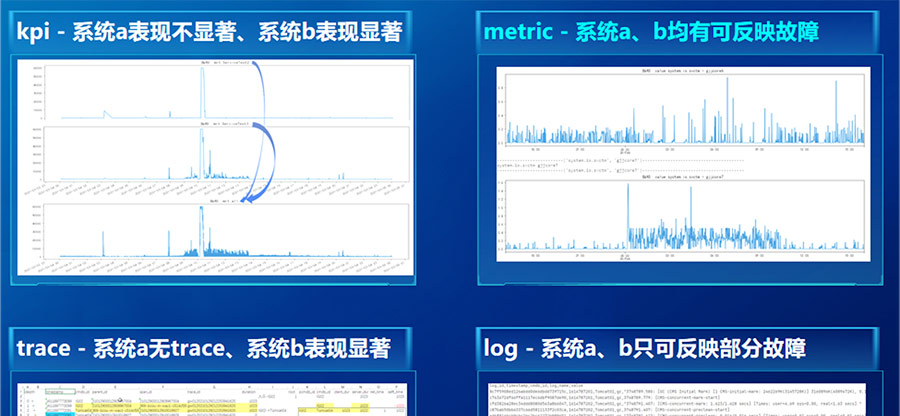
由于本次比赛中系统a、b架构不同,故障发生时系统a在kpi指标上表现不明显,系统b表现明显;而且系统a有trace数据,但是无法形成不同组件之间的调用链信息,系统b的trace数据可以统计出不同组件之间的调用链信息;另外log数据只能反映部分故障。因此我们认为本次的赛题难点是如何设计一个高度通用的异常检测及根因定位系统。
通过数据探索我们发现kpi、trace、log只是故障的间接或者部分反映,或者说表象。而且这种间接反映随系统会发生变化。只有性能指标是故障的直接反映,是所有系统的共性。因此从metric捕捉异常成为解决通用性问题绕不开的路径。
指标异常定位
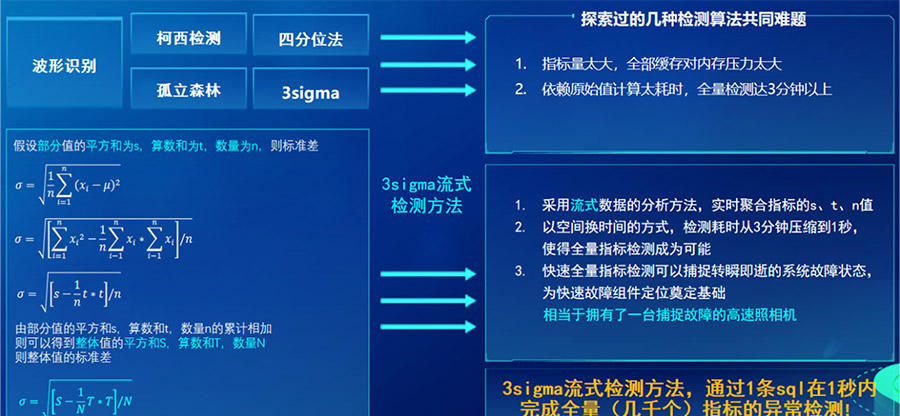
在初赛阶段,针对指标异常检测,我们尝试过波形识别、柯西检测、四分位法、孤立森林、3sigma等检测方法,但是这几种检测算法存在2个共同难题:
1. 指标量太大,全部缓存对内存压力太大;
2. 依赖原始值计算太耗时,全量检测达3分钟以上。
鉴于以上问题,在初赛阶段我们的成绩不算特别理想,通过不断的尝试、摸索,在复赛阶段我们探索出了一种高效的3sigma流式检测方法,其核心思想是,通过对3sigma中标准差公式的拆分,我们只要实时统计部分值的平方和为s,算数和为t,数量为n,则可以累计相加得到整体值的平方和S,算数和T,数量N,进而计算出整体值的标准差。这样无需依赖指标原始值,仅根据实时聚合的值就可以高效的开展异常检测了。
最终我们是在数据库中,通过1条sql在1秒内完成全量(几千个)指标的异常检测。这种高效的全量指标异常检测方法组成了地震模型的基石。
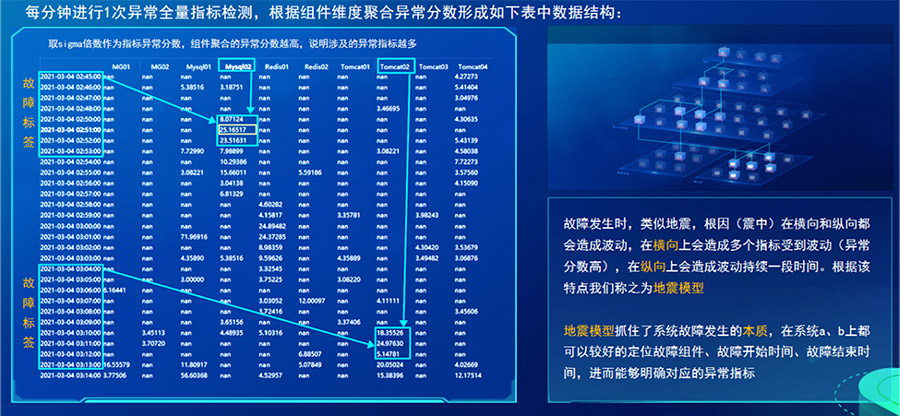
我们每分钟进行1次全量指标异常检测,根据组件维度聚合异常分数形成上图中数据表格结构,这里取sigma倍数作为指标异常分数,组件聚合的异常分数越高,说明涉及的异常指标越多。由上图可见,组件聚合后的表格能够较好的匹配官方发布的两个故障标签。
在故障发生时,类似地震,根因(震中)在横向和纵向都会造成波动,在横向上会造成多个指标受到波动(异常分数高),在纵向上会造成波动持续一段时间。根据该特点我们称之为地震模型。
地震模型抓住了系统故障发生的本质,在系统a、b上都可以较好的定位故障组件、故障开始时间、故障结束时间,进而能够明确对应的异常指标。
日志异常分析
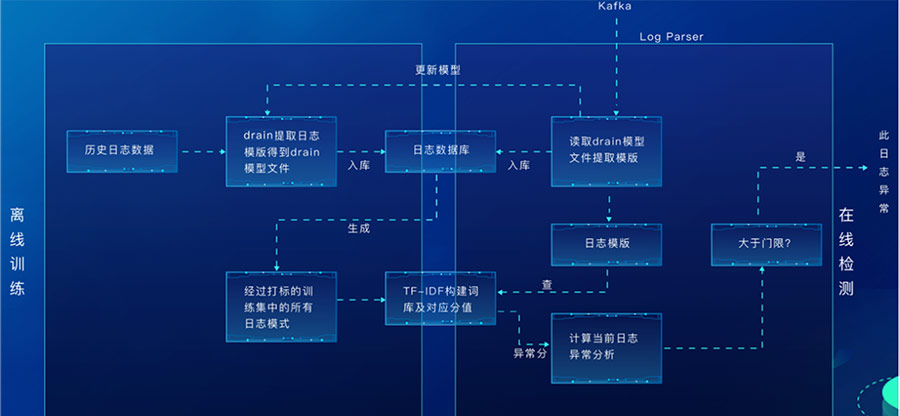
日志异常分析分为离线训练、在线检测两部分。
离线部分针对历史日志采用drain算法提取日志模板,然后通过对比故障标签,为日志模板打标,把故障的日志模板作为一篇文章,其余作为另一篇文章,然后对所有日志模板分词得到词库,计算每个分词在故障日志模板文章中的TF-IDF值,作为分词的异常分数值。
在线检测部分,接收来自kafka的实时日志数据,采用drain算法实时解析日志模板,针对日志模板中每个分词的异常分数求和,如果该值大于我们根据故障标签总结出的门限,则认为日志出现异常。
根因定位

根因定位分为两步:
- 形成因果图:这里首先采用FP-Growth算法分析出异常指标之间的相关性,然而相关性不一定能代表因果性,所以这里还对FP-Growth的结果做了一定的裁剪工作,异常指标之间的置信度必须大于0.5,且正向和反向的置信度差值必须大于0.2,相关关系中取置信度大的方向作为因果方向,这样就形成了因果有向图。
- 基于因果图发现根因指标:有向图可能存在有向环等较麻烦的问题需要解决,在这里我们规避了复杂的有向图遍历问题,而是借助简单层次分析法,使用两两指标之间的置信度构建判断矩阵,采用列归一化后,行求和(无需归一化)的方式计算出每一个指标接近根因的权重值。通过数据探索我们发现权重值在0.95以下的指标基本不可能是根因,只保留0.95以上的指标作为候选根因,且层次分析法的指标结果权重越高,越接近根因。
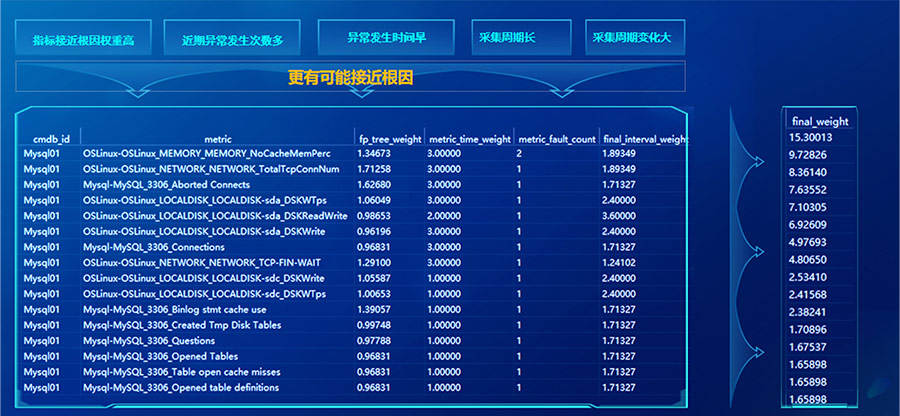
在候选根因中,除了指标接近根因的权重外,我们还额外考虑了指标在其它的几个维度的权重,如近5分钟内异常发生次数多、异常发生时间早,针对不同采集周期的指标,如磁盘指标的采集周期比较长,在之前几个维度的计算中是比较吃亏的,因此把指标的采集周期长度、周期变化程度也考虑的进来。最终这几个维度的值相乘计算出综合权重,按综合权重final_weight列倒序排列,取topN作为最可能是根因的指标。
/ 方案总结 /
最后总结下我们的地址模型方案。

亮点:
1. 指标异常检测快,可在1秒内完成全量指标异常检测
2. 故障定位通用性高、推广性强,地震模型判定故障组件的方式可以适配不同架构的系统
3. 根因定位方式简洁、维度全面,相关性+层次分析法过滤掉不是根因的指标,同时综合考虑指标异常发生时间、次数、采集周期等因素
优化空间:
1. 3sigma检测的不足,对3sigma流式方法检测不出来的故障类别,还需要针对故障类别确定关键指标,使用关键指标采用耗时的孤立森林等检测算法检测
2. 存在少量地震模型表现不明显的故障点,还需要综合考虑kpi、trace异常检测,明确故障时间点,再筛选相同时间范围内,地震模型检测异常最高的组件作为故障组件