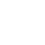国泰君安:证券业智能运维算法创新探索
发布时间:2022-10-26 18:29:00
近年来,我们开展基于机器学习与运维大数据的智能运维体系建设,在此期间智能运维算法一直在快速地发展:从数据角度看,算法分析对象包括性能指标的时间序列数据、日志告警数据以及近两年持续完善的CMDB、调用链等基于拓扑图的数据;从应用场景来看,当前主流智能运维算法包括指标异常检测、容量预测、日志聚类、日志日常检测、告警压缩、根因定位等。
在近几年的持续运营中,我们看到了AI赋能IT运维带来的效益,但也发现了并不是用了AI,异常检测、故障定位的效果就一定很好,这取决于很多因素:
首先,数据作为一种资产,它的价值有没有被充分挖掘与利用?
其次,算法作为一种策略,它是否贴合运维需求?
最后,场景的“和而不同”是智能运维发展的难点,该如何应对?
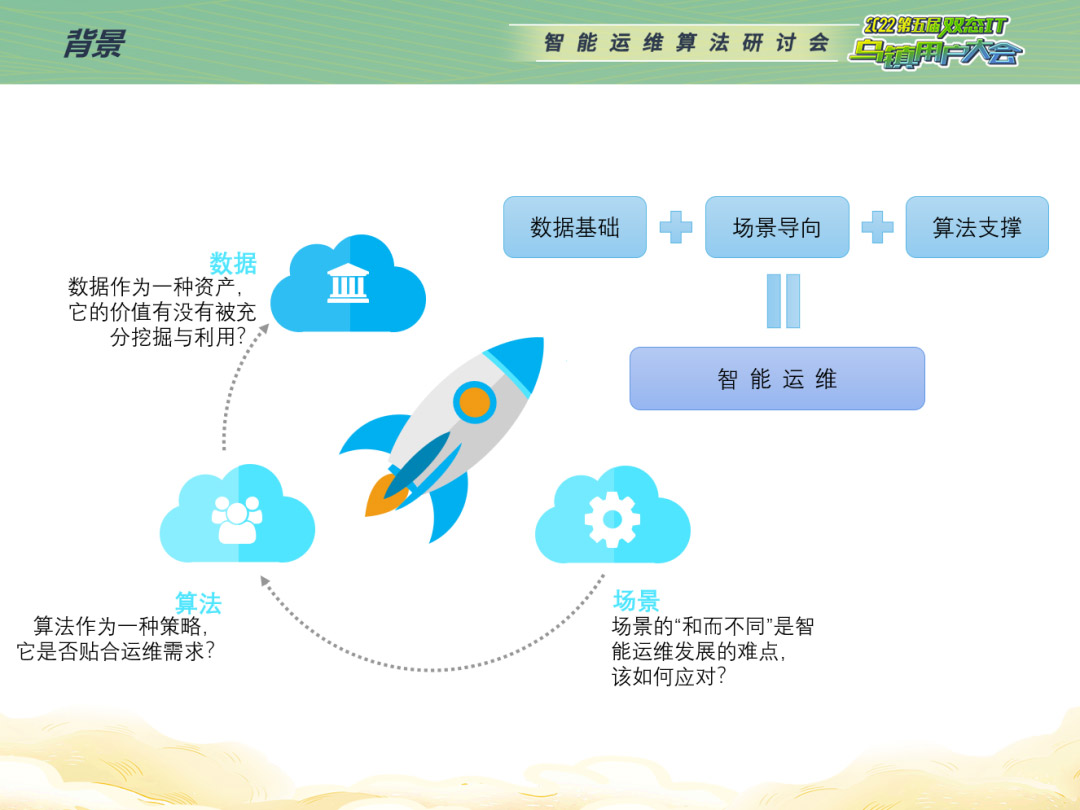
总得来说,智能运维的发展趋势以数据为基础、以算法为支撑、以场景为导向。这个也是我们智能运维国标的核心观点之一。正如《算法之美》一书中所说,“算法难以解决的问题是:规则不明确、信息不全、无数种可能性和人心。”当前,智能运维算法所面临的挑战主要有如下三点:
一、算法适应性不足
无法适应数据缺陷。
其一,数据的不完整性会影响人工智能算法的结果。由于证券行业监管要求极高,对于可反映业务特征的敏感数据无法获取,导致算法只能在有限的数据范畴内进行建模、拟合、预测。
其二,故障数据的稀疏性会导致没有足够的样本供算法学习。证券行业对后台服务器运行的稳定性和安全性要求极严,系统故障本身是一个超低频的事件,并且会被快速解决,不可能再出现。而算法需要基于历史数据学规律进行优化提升,如果之前发现的故障后来不再出现了,那么这其实是一个悖论。
无法适应复杂架构。
由于运维系统架构复杂,关联关系成网状发展,数据驱动的算法很难做到适应性演进,过分依赖大数据,导致对黑天鹅事件无有效预测手段。
无法适应系统演进。
证券行业系统变更频繁,平台调整后,原有大数据样本无法准确反映系统真实能力,基于这些大数据样本空间得到的经验规律和特征模型无法再复用,从而无法准确分析和预测系统行为。
二、缺乏有效的反馈和修正机制
算法缺乏基于反馈的模板调整能力。难以应对“这种模板应该根据这个变量拆分”、“这个变量应该被泛化”之类的个性化需求;
运维人员和算法人员对于“故障”的理解不尽相同。这导致算法进行了无效学习或是错误学习,会直接影响算法有效性。我们时常认为智能运维的算法是开箱即用,但其实效果远不是如此,算法需要不断迭代优化。当通用的算法应用到某一个场景之后,一定会成为定制化的算法,它需要和运维数据、业务特点、运维目标等深度融合,需要不断进行打磨和适配。
三、盲人摸象式算法无法感知系统整体运行情况
产生告警,系统就一定不健康吗?没有产生告警,系统就一定健康吗?在传统的监控系统中,我们往往会关注基础监控、应用服务的接口请求量等指标,但在复杂系统中,仅仅关注单点日志或者单个维度的指标,并不足以帮助我们掌握系统的整体运行状况。比如,当CPU升高时,单指标异常检测算法产生告警,但通过分析日志发现,这是因为当天行情火爆,并发数高导致的正常现象。再比如,管理员监控的指标一切正常,但大量客户反馈页面刷新不出来,很有可能这类报错在网关层就返回了,没有到达后台系统。
讲了这么多,可能有朋友要吐槽了,明明是个运维界的王者局,怎么感觉智能运维算法的表现仿佛是个青铜?其实,这都是错觉。智能运维算法绝对是隐藏的MVP。我来给大家复盘几个送人头的场景,结合我司的创新实践,看看在运维大峡谷里面,智能运维算法是怎么打怪的。
首先,管理员上来一个first blood:“我的系统正常,为什么会告警?”
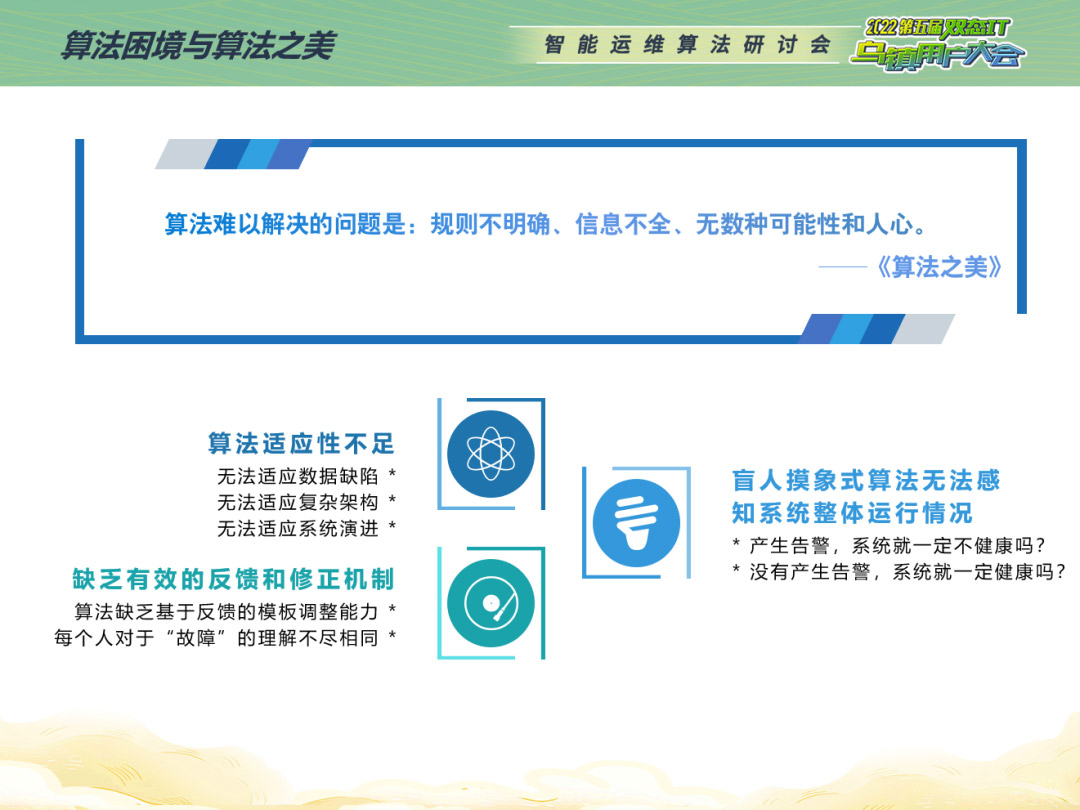
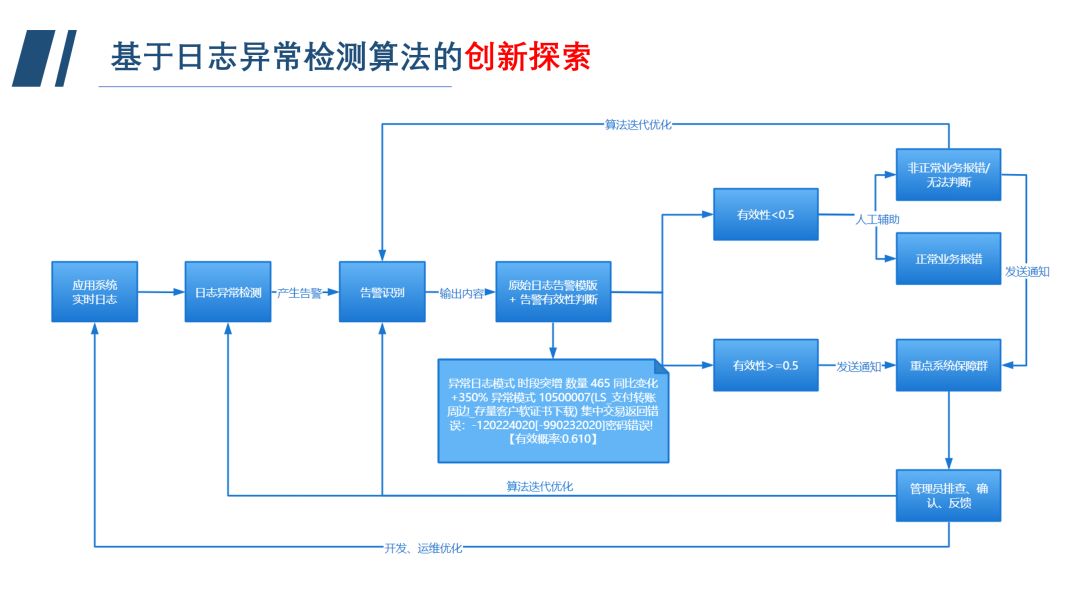
这个问题,在日志异常检测里面经常遇到。目前,很多公司都上线了日志实时聚类和基于日志的异常检测,主要解决了人工难以处理海量日志数据、基于规则的方法维护性差的问题。我们通过日志的相似性进行聚类,对日志模板的频率变化进行检测,将未匹配日志及频率改变的日志进行告警提示,辅助运维人员快速定位异常。

在我们公司,日志异常检测收获了管理员的高度认可,但也存在一些问题:大量无效告警的干扰;在提升平台可靠性同时,增加人力运营成本;管理员对于告警的个性化需求;系统不断演进,故障模式不断更新。
我把它抽象成一个二分类问题,根据告警是否为正常业务报错,可给出每条告警的0/1标签,运用机器学习算法构造分类器,通过对历史数据的学习,来预测新告警的label所属类别。老技术的新应用,这是本算法的第一个创新所在。此外,为了避免单一分类器带来的算法偏见性,我们基于“投票思想”,提出融合二分类模型,这是本算法的二次创新。
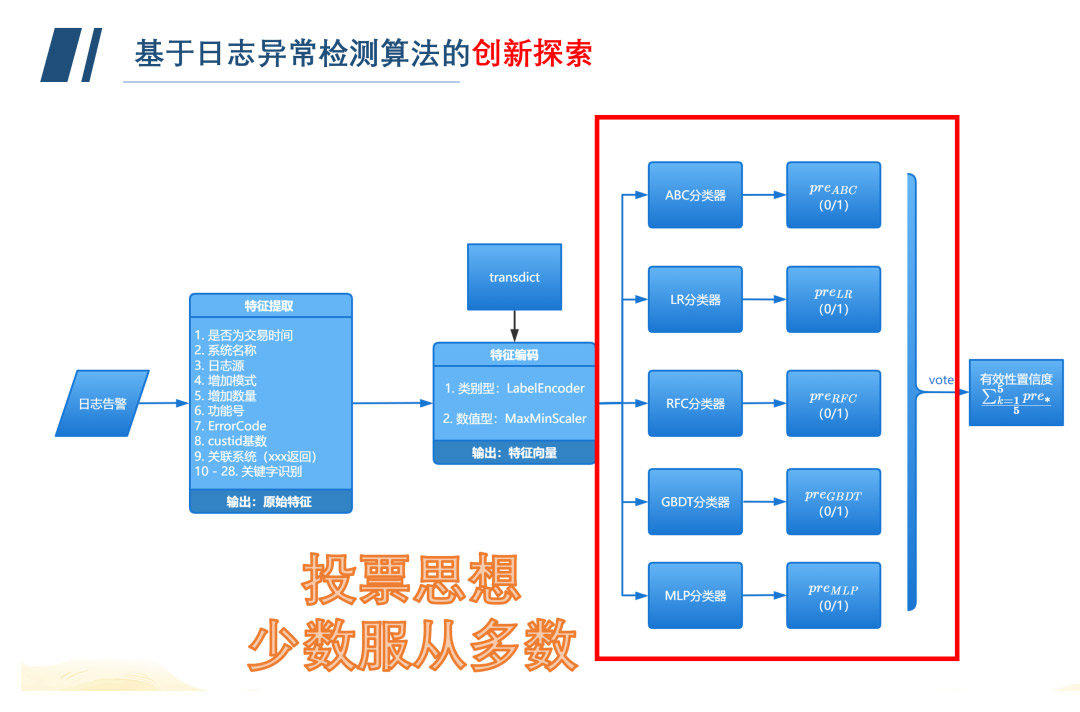
我们的运营流程如下图所示。在验证阶段,随机抽取已记录告警的20%作为验证集,融合模型的准确率、召回率均达到100%。目前算法已经上线运行快一年了,算法的实战准确率达到85%,比单纯的日志异常检测算法高出15%,此外,在人力成本上,我们从以前的人控 996追踪,到现在的技控,算法助攻我们节省了75%的时间成本。可以说这个小算法是站在巨人的肩膀上,取得了不错的战绩。
下面,再来看看管理员的double kill:“我的系统异常,为什么没告警?”
这是指标异常检测常遇到的问题。因为指标异常检测产生的告警,被管理员屏蔽得差不多了。指标异常检测是当前落地最多的智能运维场景,学界和业界提出了大量指标异常检测算法,包括单指标异常算法、多指标的异常检测算法、基于统计或深度学习的异常检测算法以及有监督、无监督的异常检测算法。
但是,算法很丰满,现实很骨感。以时延类指标为例,存在这几种问题:
时延类指标毛刺多、无规律,经常会产生误告,就像狼来了,时间久了,大家对算法就产生了信任危机。我们为了减少误报,最简单粗暴的方式就是调整算法容忍度,让基带变宽或是让告警条件变严苛。但这样不可避免地会产生漏告。所以,在降低误告和防止漏告之间,指标异常检测还需要再进行一波“猥琐发育”。
小调用功能号难以有效监控。小调用功能号的指标比较稀疏,很难生成有效的基带。
干扰项。有些功能号耗时本身就很高,如果仅仅从数值上做监控,很有可能会掩盖掉真正出现异常的功能号。
缺乏可解释性。难以对指标异常进行类型、主机、时间段、业务等方面的展示和分析,难以对异常进行交互式探索,因此无法判断异常是否应该报。
解决问题的关键在于如何衡量异常程度,具体来说,我们要回答有没有、全不全、准不准、快不快、好不好这5个问题。
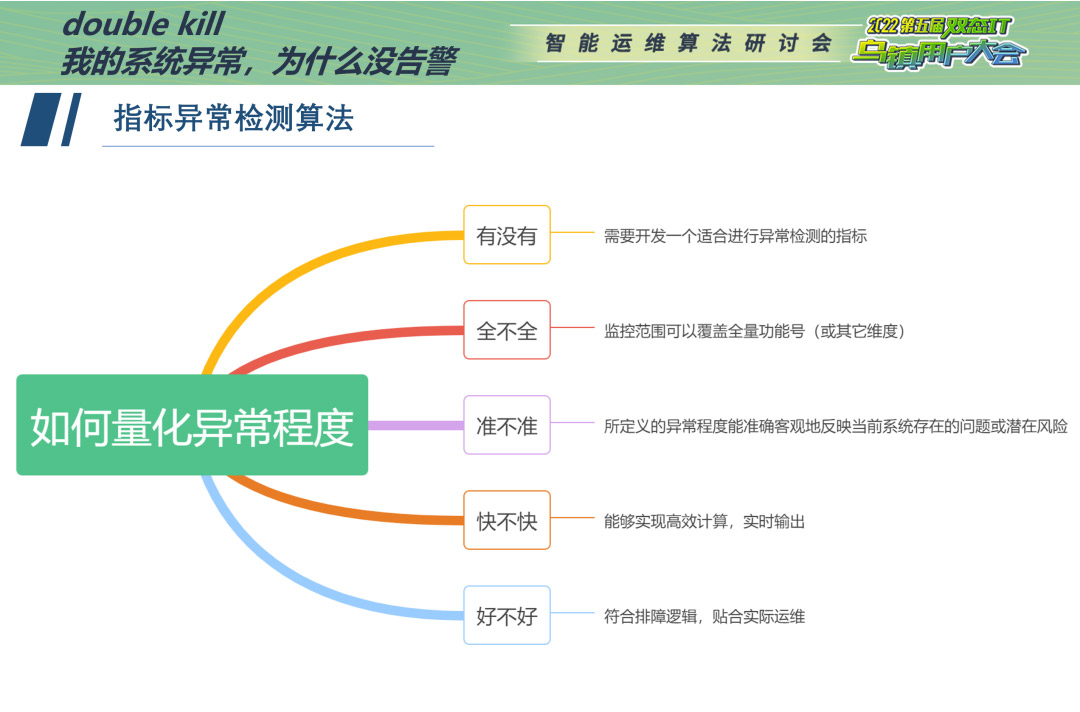
机器难以解决的问题,但人可以。我们的系统管理员在我们的一体化运维平台配置了用于统计功能号耗时大于1000ms个数的场景监控,并观察统计量TOP榜单。当他发现某功能号超时量突然增多,进入榜单时,就预示着可能有故障。管理员并不关心常年榜首的功能号,更关心进入榜单的“新面孔”。好比微博热搜,我们更倾向于点开新进热搜榜的新鲜事。
基于管理员的运维逻辑,我们首先在指标设计上进行了创新。我们以30s为粒度,统计功能号耗时超过某一阈值的个数。该指标可以直观地反映异常调用,同时也可以自适应毛刺、数据缺失等缺陷,充分发挥出数据本身的价值。
本算法的核心创新点在于:首次引入功能号排名思想,有利于监控全量功能号,有利于挖掘稀疏型指标的异常;首次引入加权熵思想,可根据耗时的不稳定性提前预警潜在风险;首次提出general anomaly score,在长短期趋势预测的基础上,考虑从功能号超时量的修正变化率、超时量排名的变化率两个维度找到变化最明显的功能号。
在实际应用中,依托强大的flink日志转指标,和巧妙的异常量化方式,算法实现轻量计算,秒出结果;算法也充分吸收并尊重管理员的运维经验、运维习惯。
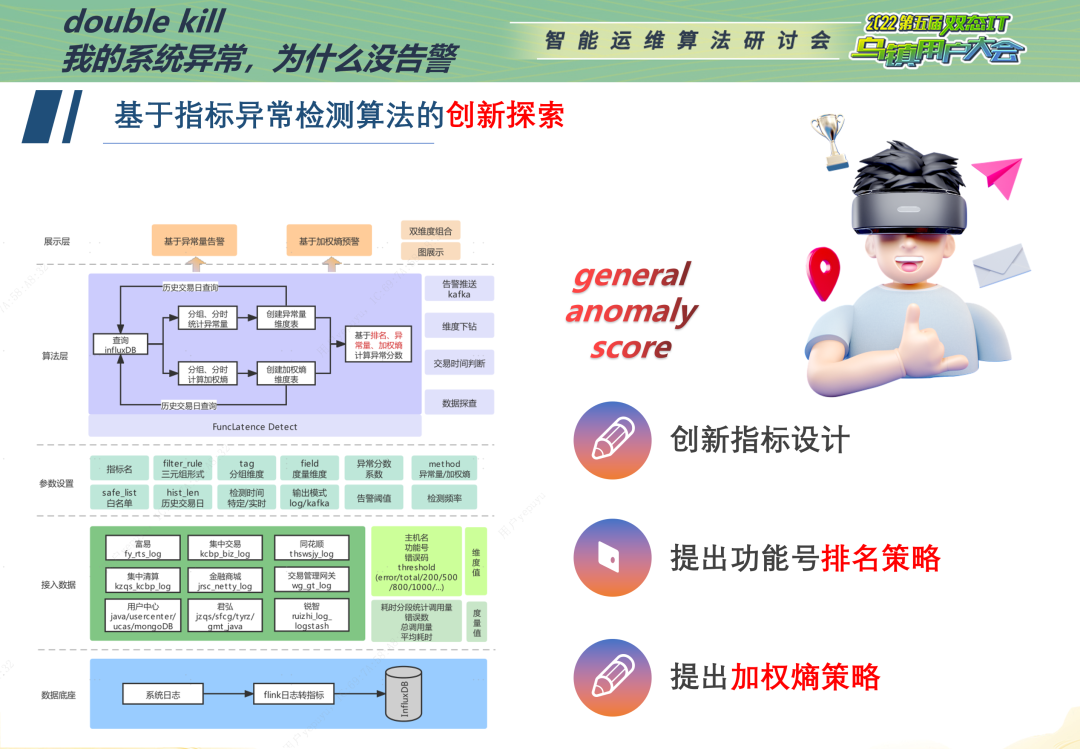
算法的总体实现逻辑如上图所示。自下而上看,分为数据底座层、数据接入层、参数设置层、算法层以及展示层。算法较好地捕捉到流量超限、数据库重启、客户异常交易等多种异常情况,提高运维监控效率,同时也与现有的指标、日志异常检测相互补充,持续为智能运维平台赋能。
最后,我们再来看个管理员的灵魂拷问triple kill:“我还是不知道系统的健康状态。”
IT平台是一个高度动态发展的极其复杂的网状系统,尽管大数据的收集越来越容易,但随着从微观到宏观的尺度变化,系统行为会发生非线性的变化,这让模型构建、行为预测困难重重。如何跨越系统的尺度变化,挖掘出对系统行为真正起到影响的重要信息,是复杂系统研究要解决的核心问题。
我们认为解决这些问题的关键是关注系统的运行模式在不同尺度上的关联方式,这些大尺度的运行模式可以被直接刻画,而不需要映射所有错综复杂的细节。这个方法由物理学相变中“重整化群”的研究中发展而来,并被推广到多尺度信息理论。
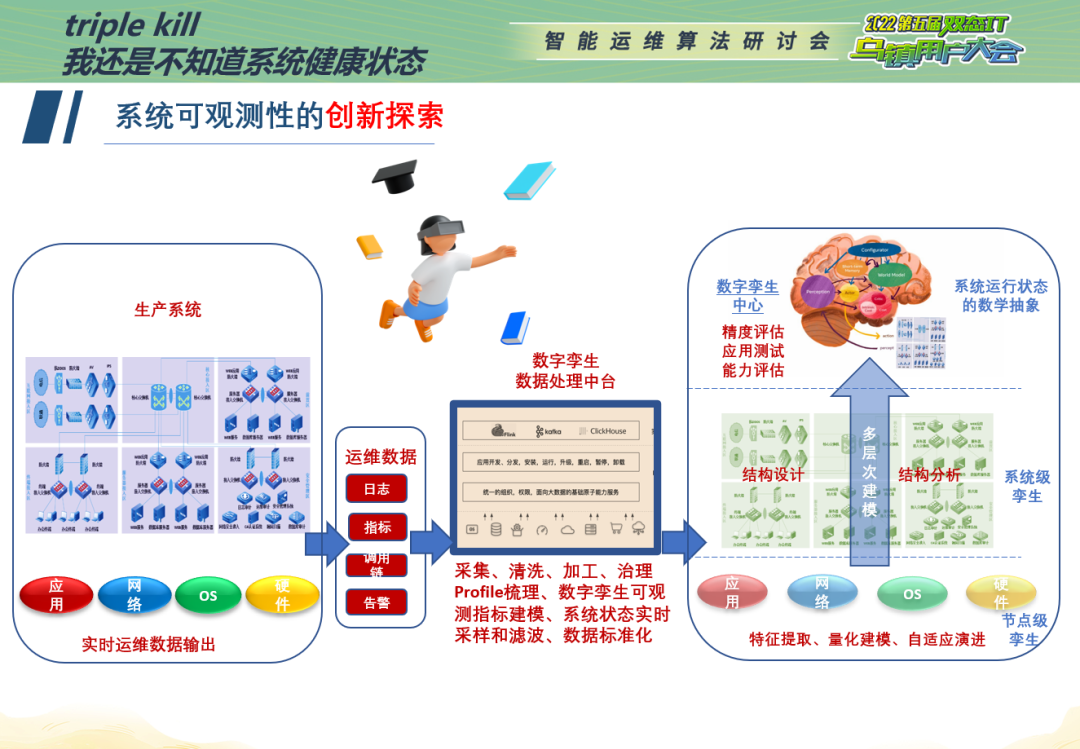
在这样的背景下,我们提出了如下解决思路:从数据驱动的黑盒方法演进到灰盒、白盒模型,逐步构建复杂IT平台的数字孪生镜像。
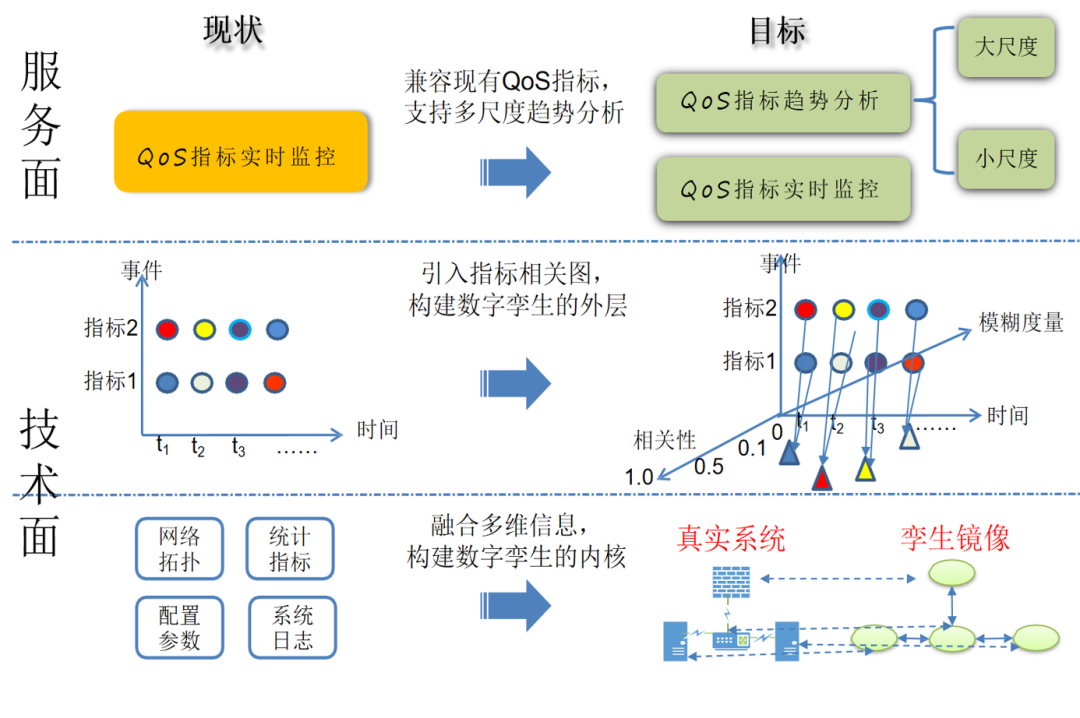
我们引入非叠加性测度理论来量化模块间的相互作用,该模型的突出特点是模型变量之间的相互作用对关键指标QoS的贡献能够用广义非线性非可加积分来定量评测。对于单个节点来说,我们可以将每个节点的CPU、memory、磁盘I/O等作为源指标,平均处理时间作为目标指标,也可以把各功能号时延作为源指标,平均处理时间作为目标指标。源指标X对于目标Y指标的影响贡献并非是单个X对Y影响贡献的简单线性叠加,而是非线性的叠加关系。我们通过引入Choquet积分,这是一种定义在不可加测度集合上的Lebesgue积分,来计算每个源指标对目标指标的贡献大小。实际在计算的时候呢,我们会获取Q组观测值,构造一个Q*N的矩阵进行求解,像下图中右上角展示的这样。这样给定一组指标观测值,就可以用最小二乘法使δ^2最小,进而求出最优的μ。
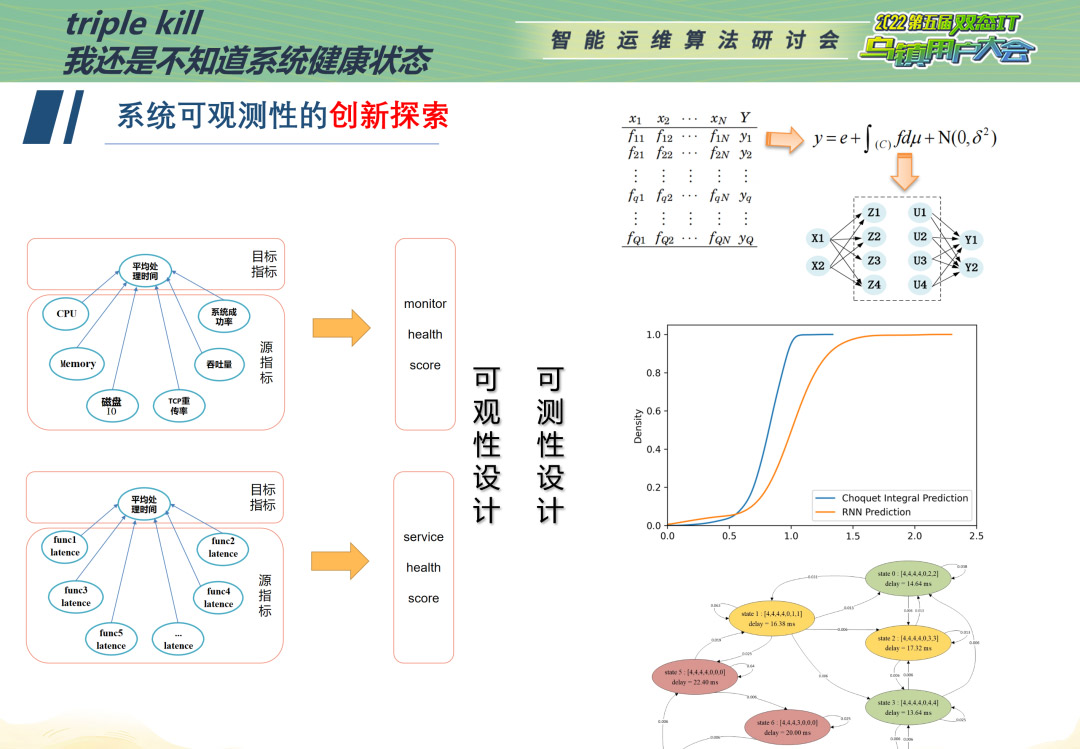
为了验证Choquet积分得到的模糊测度是否可以合理地表征系统状态,我们设计了一组对比实验。利用模糊测度的方法和RNN神经网络来训练和预测系统的Qos指标,得到相对误差概率分布曲线。从概率密度的对比来看,模糊测度方法得到的预测误差更低且更稳定。
前面说这么多,我们其实都在干一件事情,就是“小尺度测量”,那接下来,我们要做的是大尺度建模。大尺度建模是基于小尺度测量的基础上对小尺度测量模型进行量化、离散化,以离散马尔可夫链模型刻画节点在不同小尺度测量模型上的动态迁移过程,从而在较长时间尺度上构建节点的运动规律。
在上图右下角所示,每个椭圆代表一个状态,椭圆内注明状态的详细信息,包括权重离散化结果,该类状态的平均时延,并且根据时延的大小,我们对时延的高低进行了简易的标注(从红色黄色绿色依次表示时延从高到低),使得系统的性能状态的转移更加清晰。箭头表示状态转移的关系,
最后,每次更新状态时采用α滤波算法更新节点输出指标的平均值,如果新的观测值大幅超过该平均值,现在设定的是2.5倍,我们就认为该节点进入异常状态,基于统计出节点的正常、异常状态比例,根据特定标准给节点健康度进行统计打分。这种健康度打分方法紧扣QoS关键指标,是以业务为导向的评估方法。该方法具有通用性,能够很好的适应指标体系设计的变化。
下面,这张图是我们一个远期的数字孪生愿景。数字孪生最开始被应用,主要是基础设施、建筑行业建模,我们是把这个概念迁移到了信息系统上面。事实上,信息系统本身也是个物理实体,通过有效的监控、观测,我们获取了系统全方位、多维度的数据,就可以把复杂的信息系统运转机制还原,从而构造出它的数字孪生体。我们现在常说数据驱动,那数字孪生的方法其实是模型和数据双驱动的可观测方式。
最后谈一点,怎么提高算法技能让它不送人头呢?那我们得给算法加点蓝(buff),尽快生成一个大招。《算法之美》这本书,里面最精彩的一句话是“最重要的永远不是解法,而是决定解决什么问题。最优算法总能找到,前提是确定度量标准。”
那我们对智能运维算法,可以提哪些度量标准呢?在这里,我也抛砖引玉一下,主要三点:算法设计能力、运维场景的理解能力和平台的工程化能力。

算法设计能力。
用户的需求是个性化的,需要根据用户的需求设计针对性的算法,充分发挥数据价值。
运维场景的理解能力。
算法只是手段,运维才是最终的目标,算法必须结合运维场景,只有深入研究并理解运维场景,才能发挥出算法的效用。
平台的工程化能力。
针对目前海量的数据环境,大规模的运维数据处理需要高效稳定的数据平台,此外还要同算法进行高效地结合,提高平台的数据处理分析能力。
算法正在智能运维中发挥越来越大的作用,但算法落地仍有大量问题亟待解决。算法不能一蹴而就,需要赋予其持续优化能力。不妨将算法作为一种运维的辅助手段,使运维人员也能灵活地分析数据,在运维过程中使其变得更高效。
最后,我想以我们数据中心总经理曾宏祥曾总的一句话结束演讲:“未来,我们还要以谦卑的态度保持对新技术的渴望和探索,提升每个人的专业价值和团队的战斗力,以孜孜不倦的创新精神重新定义运维,走向智能运维的星辰大海。”