KnowLog:基于知识增强的日志预训练语言模型|顶会ICSE 2024论文
发布时间:2024-04-02 10:21:47

徐波 东华大学副教授
东华大学计算机学院信息技术系副系主任,复旦大学知识工场实验室副主任,智能运维方向负责人。入选“上海市青年科技英才扬帆计划”。研究成果发表在IJCAI、ICDE、ICSE、ISSRE、ICWS、CIKM、COLING等国际会议上,曾获中国数据库学术会议(NDBC 2014)优秀论文奖。主持及参与国家重点研发计划、国家自然科学基金等科研项目10余项。
论文分享:
KnowLog: Knowledge Enhanced Pre-trained Language Model for Log Understanding(ICSE 2024)
KnowLog:基于知识增强的日志预训练语言模型





本文根据东华大学副教授徐波老师在2023 CCF国际AIOps挑战赛决赛暨“大模型时代的AIOps”研讨会闪电论文分享环节上的演讲整理成文。
今天分享的主题是“懂运维语言的小模型”。从今天上午的汇报来看,小模型依然很重要。即使大家都在做多智能体的协同,但是他们的底座智能体还是在用小模型来做,这可能是考虑到成本和质量的问题。此次报告将从4个方面进行分享。
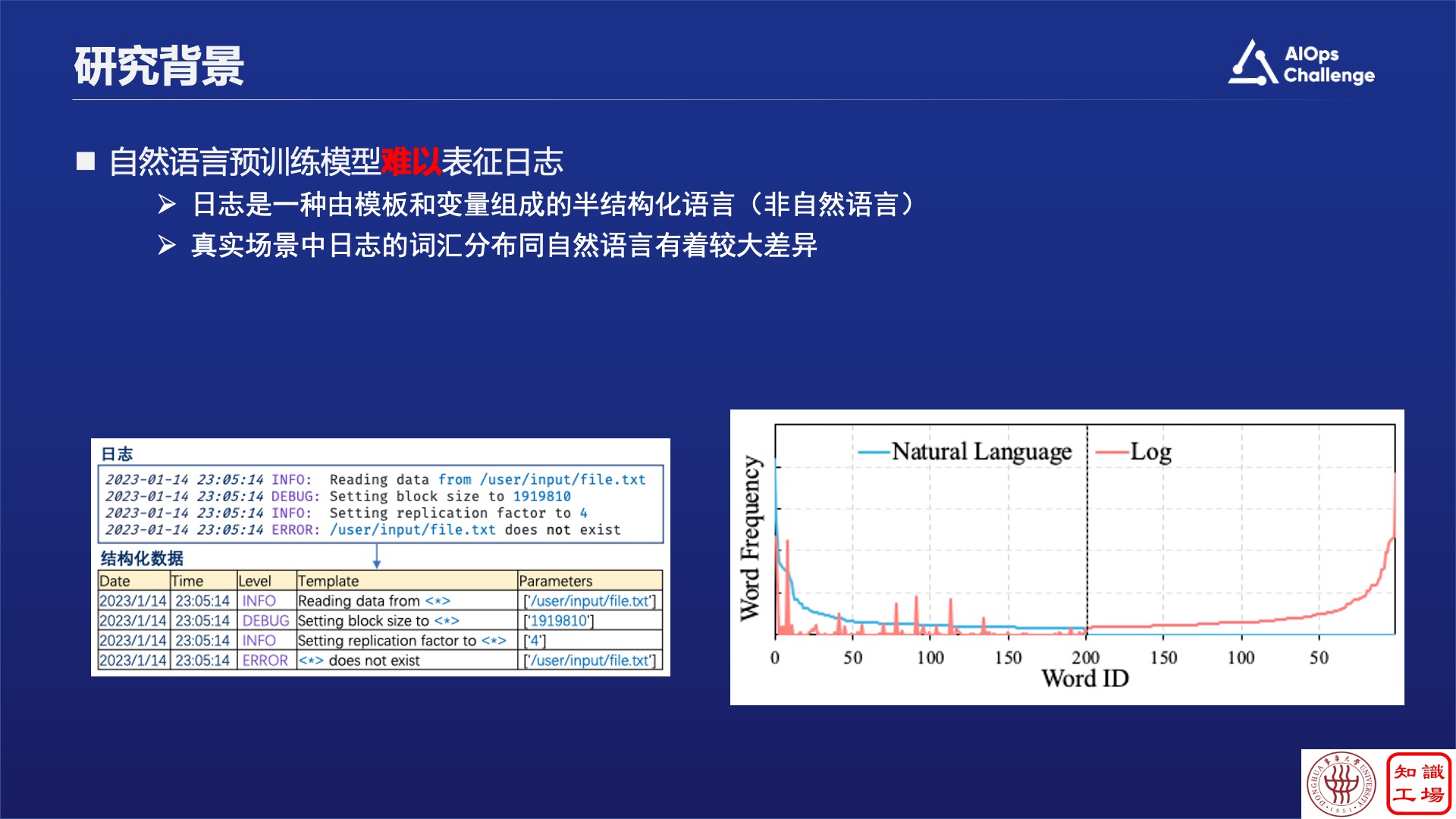
众所周知,日志在运维系统中占据非常大的比重,日志分析是一个非常重要的工作,每分钟都会有几十万上百万的日志产生,这个时候用大模型肯定是不行的。而以前的小模型,针对不同的任务,设计不同的框架去单独解决,缺乏一个统一的处理框架。
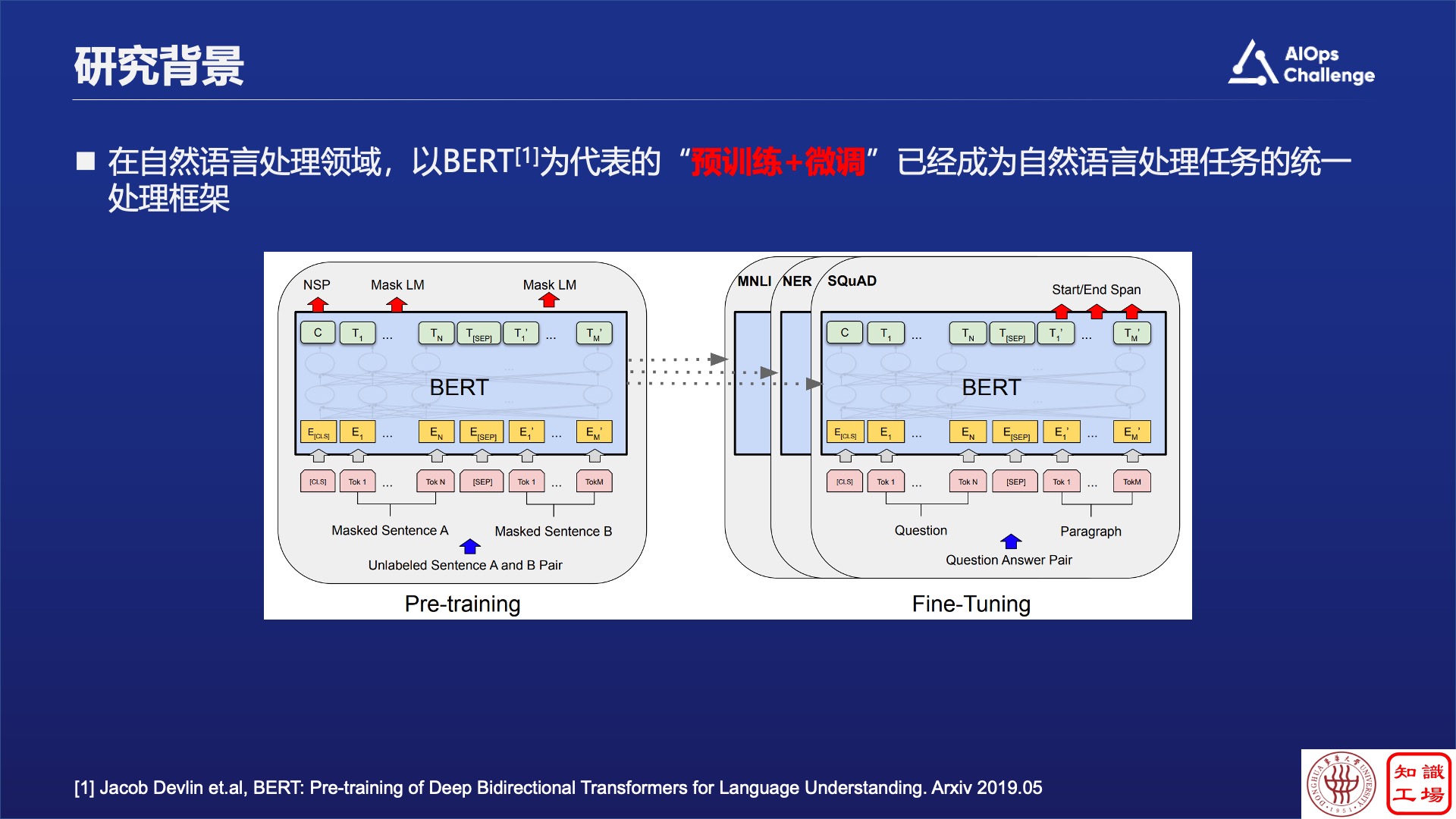
而在NLP领域,“预训练+微调”已经成为了自然语言处理的统一范式。那么能不能把这种自然语言的统一范式应用到日志里面,构建日志的预训练模型呢?
我们把这种类似BERT的预训练语言模型放到日志里面去,发现其实它并不是很work,原因是什么?分析结论是,自然语言中的高频词和在日志中使用的高频词其实是不一样的。这里就会产生三个具体挑战:
第一,通用的预训练语言模型不理解日志中的特定术语,比如OSPF或者SYSLOG等等,这些领域的特定缩写经过Bert编码后会被变成unknown,这就会非常影响后续的处理。
第二,从整体来讲,通用的预训练语言模型不理解日志到底在说什么,就像给非专业人士看日志文档,事实上也是看不懂的。
第三,不同厂商描述同一个日志打的Log也是不一样的。
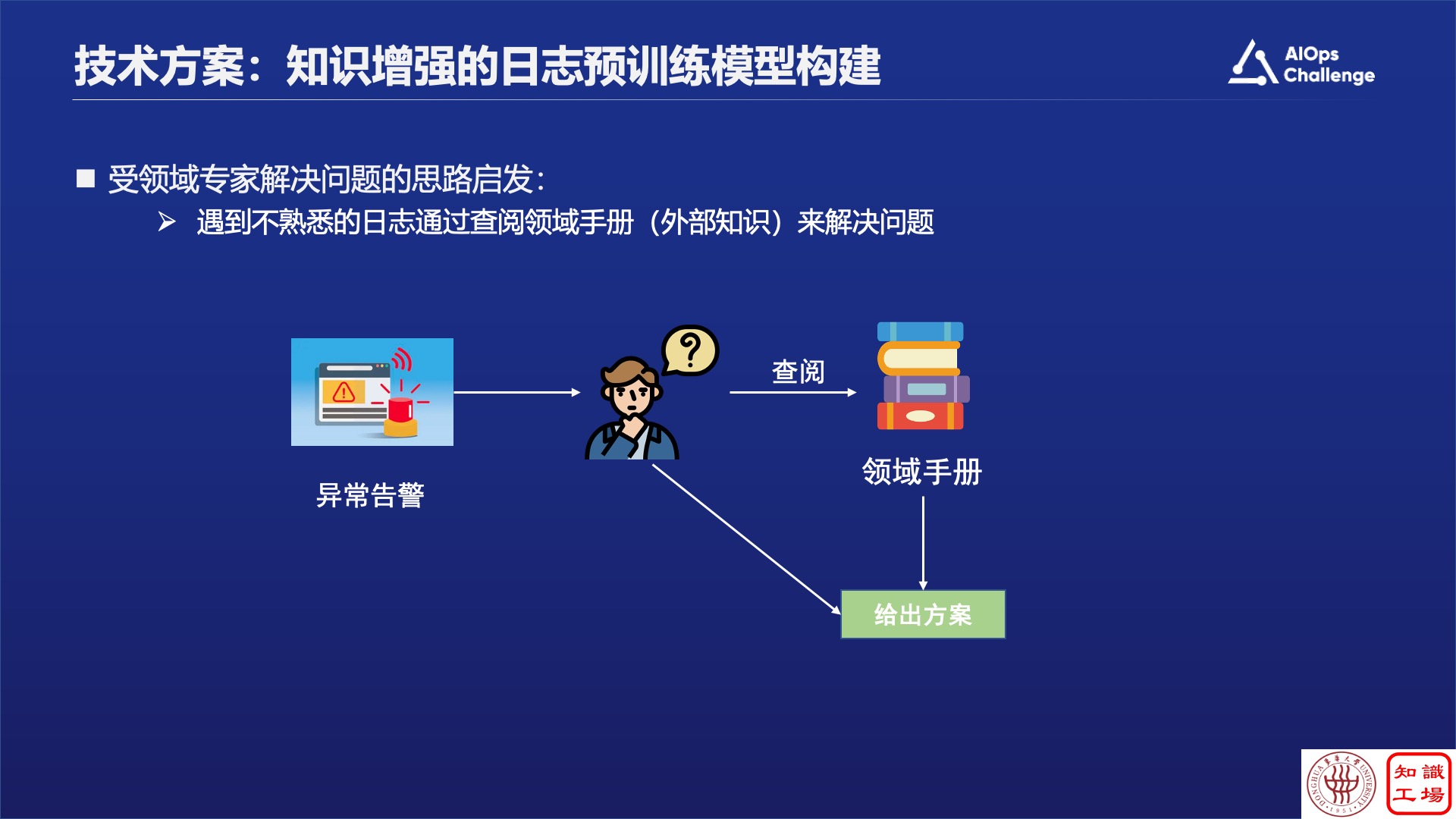
针对这三个挑战,我们受专家解决问题的思路启发提出了知识增强的方案,会去从领域手册里查询补全知识。
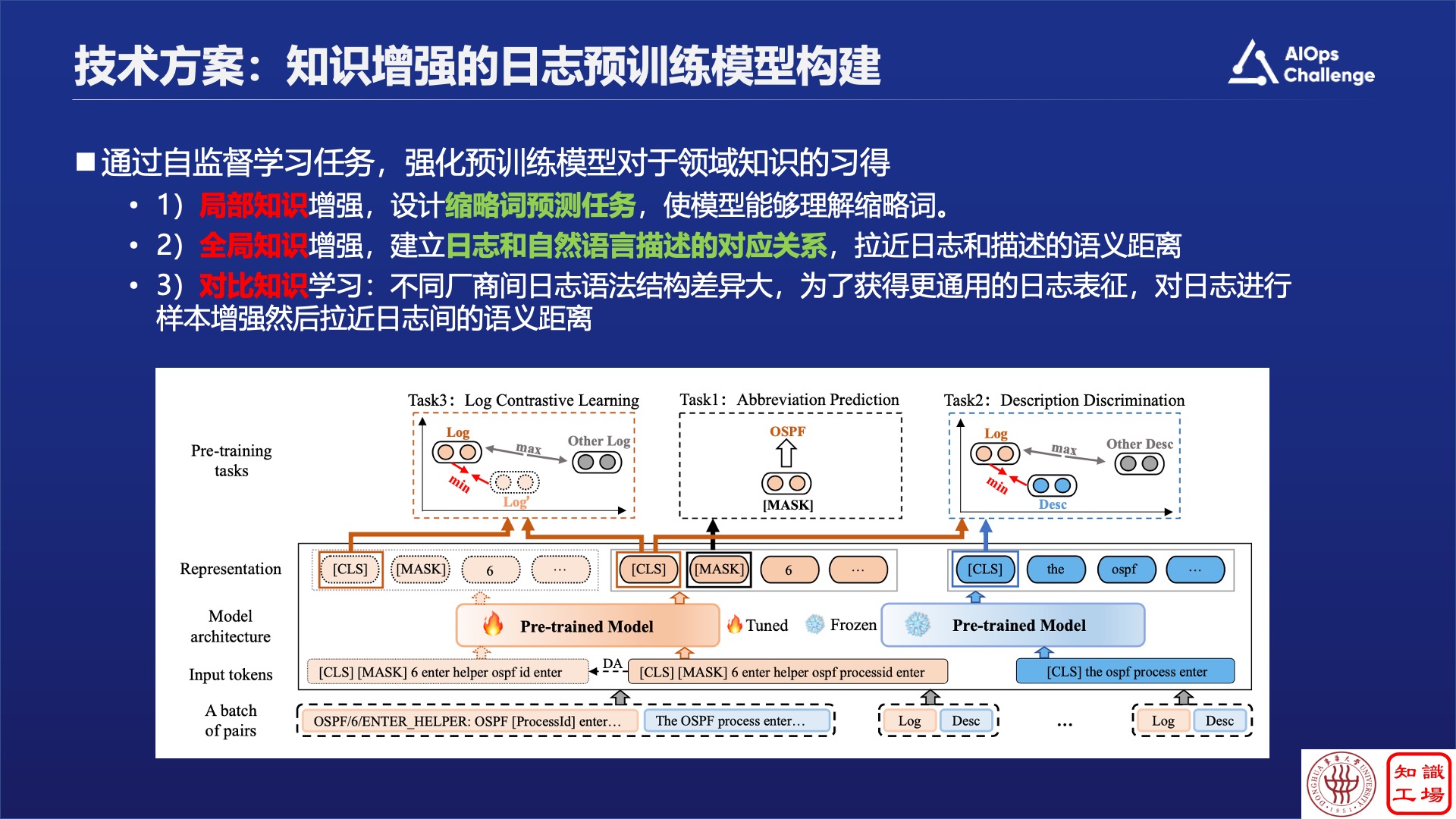
如果局部知识不懂,就看缩略词表,把局部知识补全。如果是全局知识不懂,就看全局知识描述的文档。基于以上,我们提出了知识增强的日志预训练模型的框架,该框架主要分为三部分:
第一,如何把局部知识灌到大模型里,这里设计了缩略词预测任务,把缩略词遮住之后让大模型复原,如果它知道是缩略词,就认为模型已经理解缩略词。
第二,针对全局知识的增强,建立日志模板和日志描述的对应关系。
最后,为了支持不同厂商的日志?使用了对比学习的思路,通过构造各种的数据增强方式,去对同一个日志做不同表达,使其能够满足不同的表示方法。
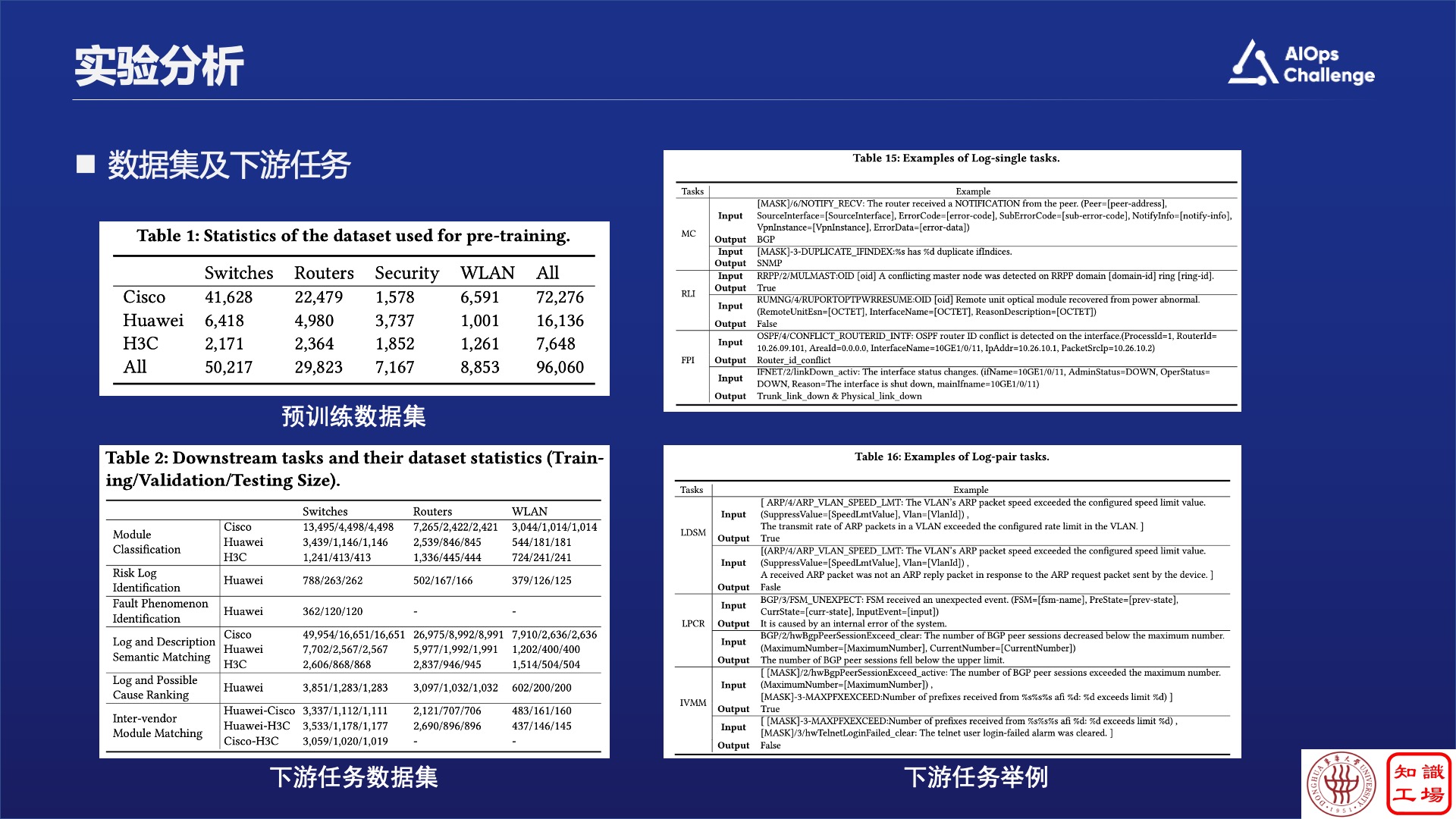
基于这个方法,我们构造了很多的实验,从华为、思科、华三等一些厂家提取日志模板。注意这里做了一个改进,就是我们没有去理解日志,而是去理解日志模板,因为日志很多,但是模板并不多。我们这边拿了10万条的日志模板,然后构造了一些下游任务,从而得到了几个结论:
首先,通过知识增强的日志预训练模型确实显著优于通用预训练模型。
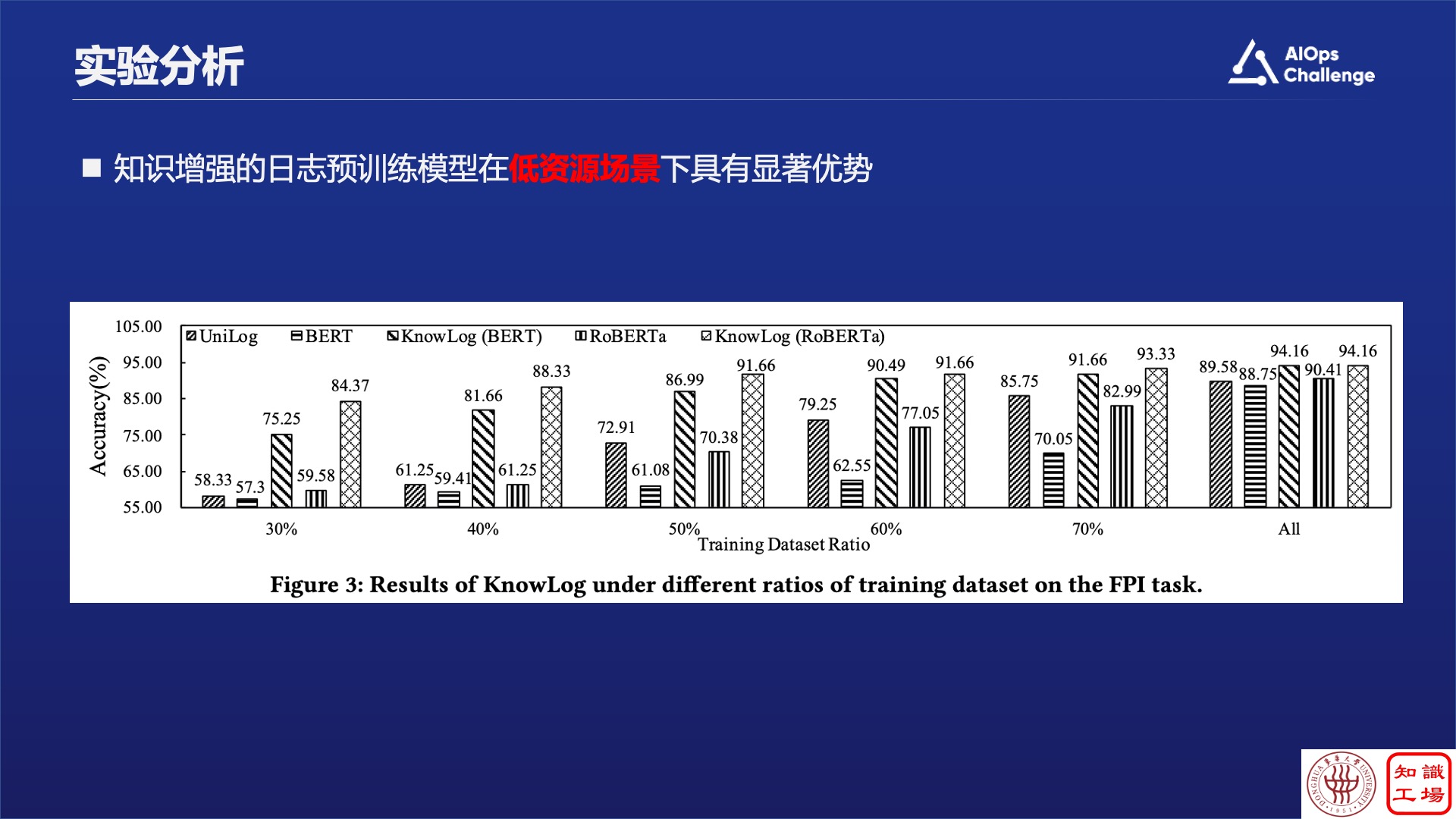
然后,在低资源场景下实验,这个实验很实用,因为企业内部的数据并不是太多,通过实验可以看出,把整个的训练集砍掉了一半,甚至只保留30%,模型下降的程度并不高,而通用模型的下降幅度就比较大。
另外,在跨厂商迁移方面,我们用华为的日志训练完应用到华三日志上面,或者用华三日志训练完去用到思科日志上面,发现都有非常好的效果。
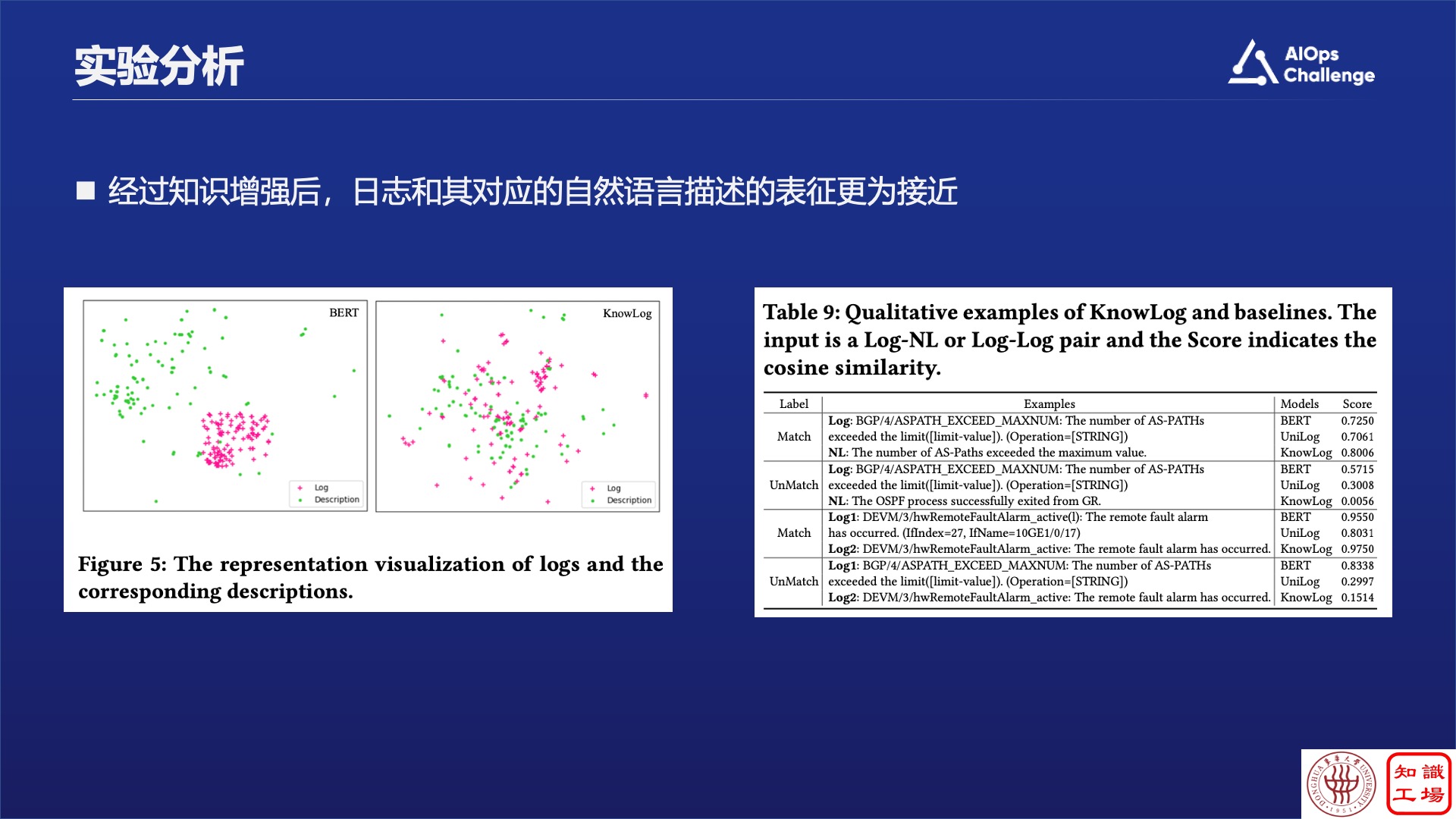
同时,通过可视化展开可以看到,在没有做知识增强之前,原始日志和它的描述其实是红点和绿点区分得非常开,但通过了我们的知识增强对齐之后,把日志和它的描述对应的比较紧密了。
总结一下,我们事实上是提了一个基于领域知识增强的框架。目前这一版的缺陷就是必须先有文档,才能做日志理解。后续还有工作就是不需要有文档,直接用ChatGPT生成。通过实验我们发现用ChatGPT,只要精心设计提示词,规范好生成结果,它也是能达到跟日志文档一样甚至更好的效果。
以上就是我的分享内容,谢谢大家。