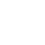移动Web系统中无监督KPI异常检测的监督式微调
发布时间:2024-03-08 14:18:00
作者:蔚兆洋,张圣林,孙铭泽,李英可,赵彦凯,花小磊,朱琳,温希道,裴丹
随着蜂窝网络的迅速发展,无线基站已成为移动Web系统的关键基础设施。为了确保服务质量,运营商通常会监控无线基站的运行状态并部署异常检测方法,以及时识别系统异常。在部署异常检测方法之后,运营商会定期收集反馈,这些反馈对提高异常检测性能具有重要价值。在生产环境中,漏报反馈的频率通常非常低,并且反馈的数据分布可能与原始训练数据显著不同。因此,已有的基于反馈微调的方法在此类场景下效果有限。
因此,文章提出了一种面向无监督异常检测的监督式微调方法——AnoTuner,它可以生成相似的漏报反馈案例,有效补偿了漏报反馈频率较低的问题。此外,文章设计了二阶段主动学习机制,降低了由反馈数据分布与训练数据分布之间差异引起的数据污染问题。文章基于中国移动的生产环境基站数据进行了实验,表明AnoTuner在基于反馈的微调后显著提升了KPI异常检测方法的性能。文章的代码已经发布在 https://github.com/NetManAIOps/AnoTuner 。
背 景
为了保障无线基站的服务质量,运营商会定期监控每个基站的各项关键性能指标(KPI)。指标的异常通常是指KPI模式偏离历史正常值或KPI之间的关系发生异常。这些异常由多种原因引起,如不正确的软件更新、基站损坏或恶意攻击。文章与中国移动确定了25个广泛使用的无线基站性能指标,这些指标形成了多变量时间序列数据,如图 1所示。
无线基站的多变量时间序列示例,红色矩形标记异常时间段
运营商通常采用异常检测方法来监测无线基站。由于机器学习在各领域展示出的卓越性能,传统基于规则的异常检测方法逐渐被机器学习方法所取代。然而,机器学习方法在生产环境中的部署面临着一些挑战。对于基于规则的异常检测方法来说,反馈数据很有效。但对于基于机器学习的方法,反馈数据的作用欠佳。由于模型训练成本较高,运营商很少频繁重新训练异常检测模型。因此,如果反馈微调未能解决问题,模型的性能问题将持续到下一次重新训练,将增加误报和漏报的风险,降低异常检测结果的可信度。
研究挑战
数据稀缺
无线基站中的异常并不经常发生,由于运营商对异常检测方法配置的偏好,漏报的反馈数据更为罕见。传统半监督异常检测方法难以有效学习漏报反馈的稀缺数据。
数据分布偏差
在部署异常检测方法后,由于软硬件升级和配置更改,收集到反馈数据的分布可能会与训练数据的分布显著不同。这种差异可能导致在基于反馈的性能改进中发生模型污染。
结构设计
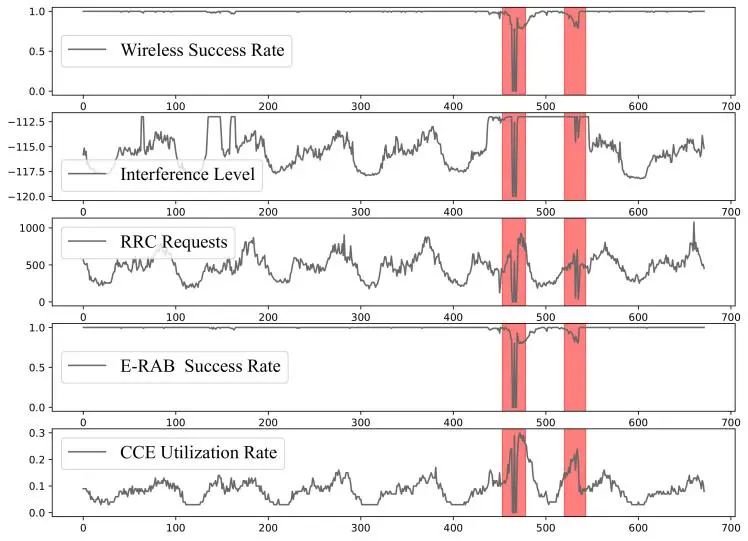
AnoTuner的整体工作流程如图 2所示,分为三个阶段:无监督训练和部署、收集反馈以及监督式微调。在反馈收集过程中,运营商定期提供有关异常检测方法报告的误报或漏报的反馈。在实际环境中,这个周期通常为一周。在基于反馈的微调阶段,AnoTuner经过两个关键步骤:漏报反馈增强和二阶段主动学习。
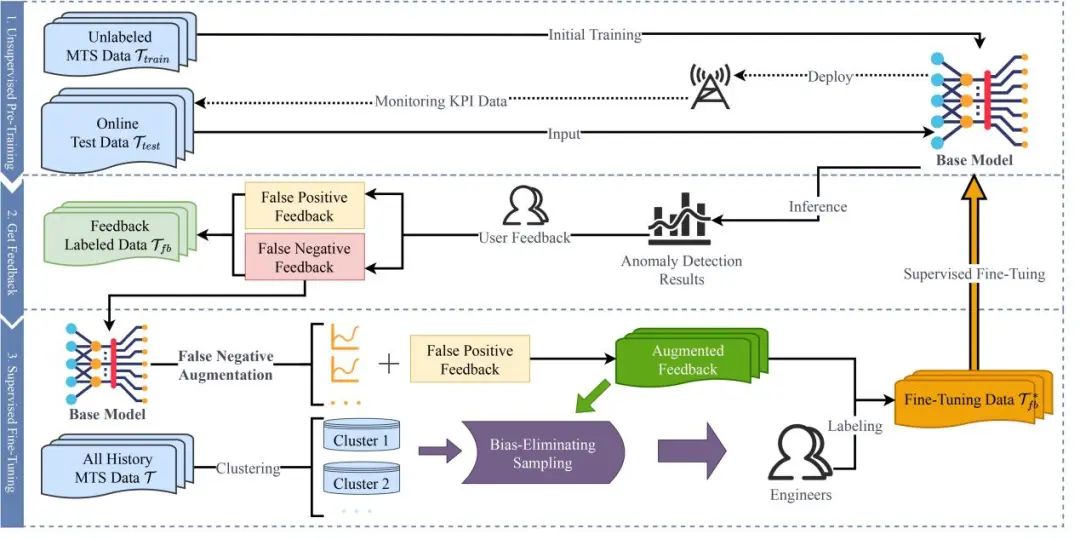
图 2 AnoTuner整体工作流程
实验评估
文章对比了AnoTuner与5个多维时间序列异常检测模型。为了评估模型从反馈数据中学习的能力,文章将实验分为四组:无反馈微调(w/o fine-tuning)、仅调整误报(FP fine-tuning)、仅调整漏报(FN fine-tuning)和同时使用误报和漏报反馈进行微调(FP+FN fine-tuning)。最终的实验结果如表1所示。AnoTuner在所有方法表现最佳,在微调后的F1-Score提升约为同样具有基于反馈微调机制的ACVAE的五倍,说明AnoTuner可以更有效地利用反馈数据。
实验结果
总 结
在当前移动Web系统中,KPI异常检测变得至关重要。AnoTuner通过结合历史反馈数据和监督微调,致力于提高模型的性能和泛化能力。文章详细讨论了KPI异常检测的挑战,包括数据有限性和模型污染,并突显了AnoTuner的创新性解决方案。AnoTuner的结构设计凸显了巧妙利用历史反馈数据和监督式微调的关键作用。实验证明,在仅占测试集0.74%的有限反馈数据下,AnoTuner在真实数据集和公共数据集上表现出色。总体而言,文章为解决有限监督数据下的KPI异常检测问题提供了新的思路,AnoTuner的引入和实验评估为该领域的发展提供了有力支持。