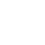通过大语言模型理解运维故障:评估和总结
发布时间:2024-02-13 10:18:00
感谢各位嘉宾对AIOps挑战赛和研讨会的大力支持,今天我将分享近期我们团队和微软合作基于大语言模型提高对故障理解的工作。
什么是云服务故障?
当今社会,我们正处在数字化时代,云服务对我们的生产生活至关重要。国内和国外涌现出一批优秀的云服务供应商:亚马逊的AWS、微软的Azure、谷歌云、阿里云、腾讯云等。它们为我们提供了各种各样的服务,让我们的生活更加便利。
但是,近期接连不断的爆出多家云服务公司出现故障的事件,当故障发生之后,一个云数据中心或整个地区的基本服务(如存储、计算能力或中间件)中断,带来了巨大的经济损失;用户体验下降,造成客户丢失。企业和个人都受到了波及,大家应该是感同身受。
当云故障发生之后,我们首先需要确认故障影响了哪些组件。只有确定了被影响组件才能够做故障规避,把这部分组件进行隔离。

以上图为例,当一个存储服务的故障发生之后,会导致数据库指标出现增长,Web App性能出现下降,进而导致用户体验降低。从“T1”时刻开始,我们可以确认这是一个故障了,因为它影响用户体验,并且造成了很多事件发生。
故障发生之后我们需要花一段时间总结故障产生的原因,也就是图片中“T2”时刻,我们需要写故障摘要,把整个故障的摘要信息告诉其他的团队。
在此之前,故障摘要的生成是通过人工的方式去完成的,费时费力且容易出错。微软在这方面做了一些事件聚合的尝试工作,但是把事件聚合完了之后,还是需要运维工程师去人工查看。这里有两个挑战:首先,需要运维工程师判断哪些信息是有用的。其次,需要总结领域特定的、与云相关的故障信息。
什么是故障的摘要?
我们分析了微软过去三年故障的数据,回答了下面几个问题。
1、故障的影响范围

我们分析了微软18个云系统3年多的数据,研究了超过6000个已经解决的云故障。发现超过86%的故障是影响了很多用户的,其中持续时间长的故障比例远大于持续时间短的故障;同时,我们还发现25%的故障关联超过10个事件,影响范围比较大。
2、故障摘要包含了哪些信息?

我们把已有的工单信息、告警信息进行分析研究,主要是分析那些级别比较高的告警信息,进行整合生成故障摘要。在这个摘要里主要回答了五方面的问题:故障出现的时间、故障发生的位置、故障影响的范围、故障如何产生、为什么会发生故障。把这些问题总结之后就能够生成如上图右边实例的故障摘要。
 技术框架方案介绍
技术框架方案介绍
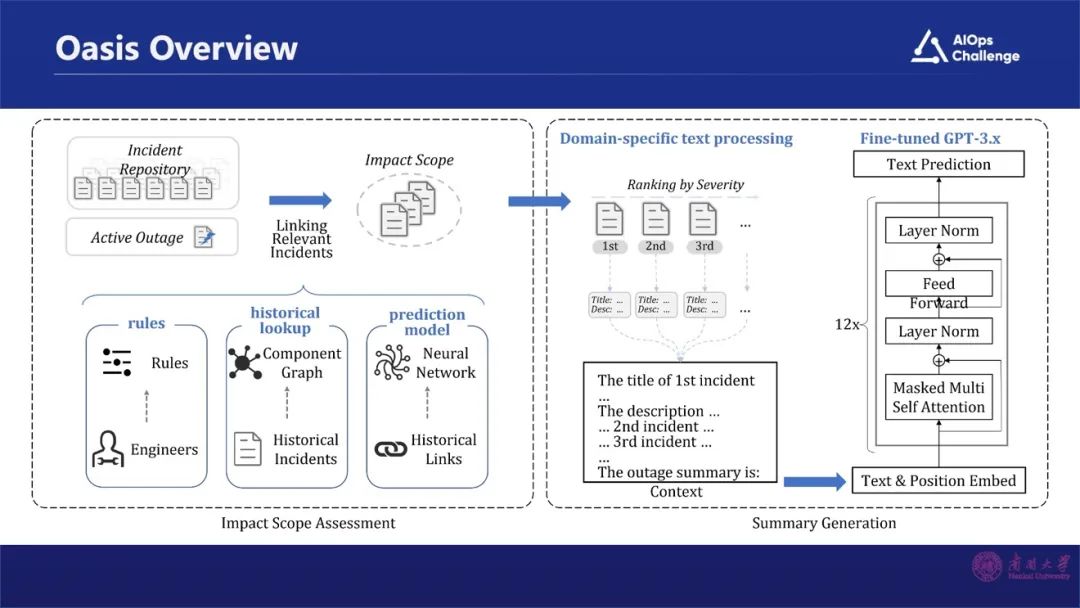
我们把已有的工单信息、告警信息进行分析研究,主要是分析那些级别比较高的告警信息,进行整合生成故障摘要。在这个摘要里主要回答了五方面的问题:故障出现的时间、故障发生的位置、故障影响的范围、故障如何产生、为什么会发生故障。把这些问题总结之后就能够生成如上图右边实例的故障摘要。
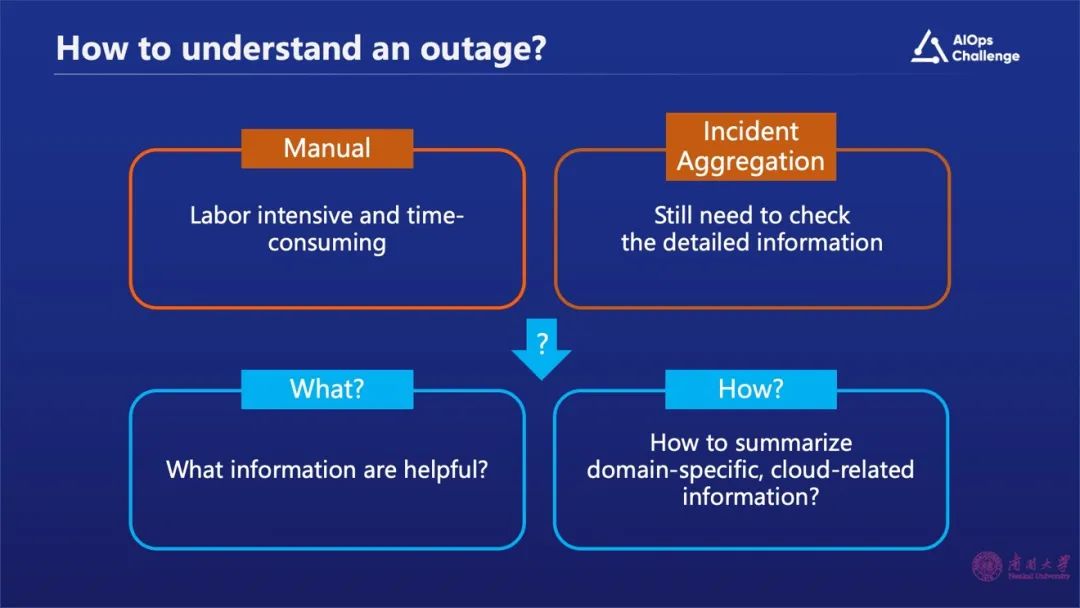
3、人工分析故障所需的时间成本
我们做了一个统计,如上图所示“T1”代表了故障开始时间, “T2”代表运维工程师写完故障摘要的时间,用“T2”减“T1”表示整个故障摘要生成的时间。我们会发现超过23%的故障花费的时间是超过两个时间单位的,耗时比较长。
4、研究结果
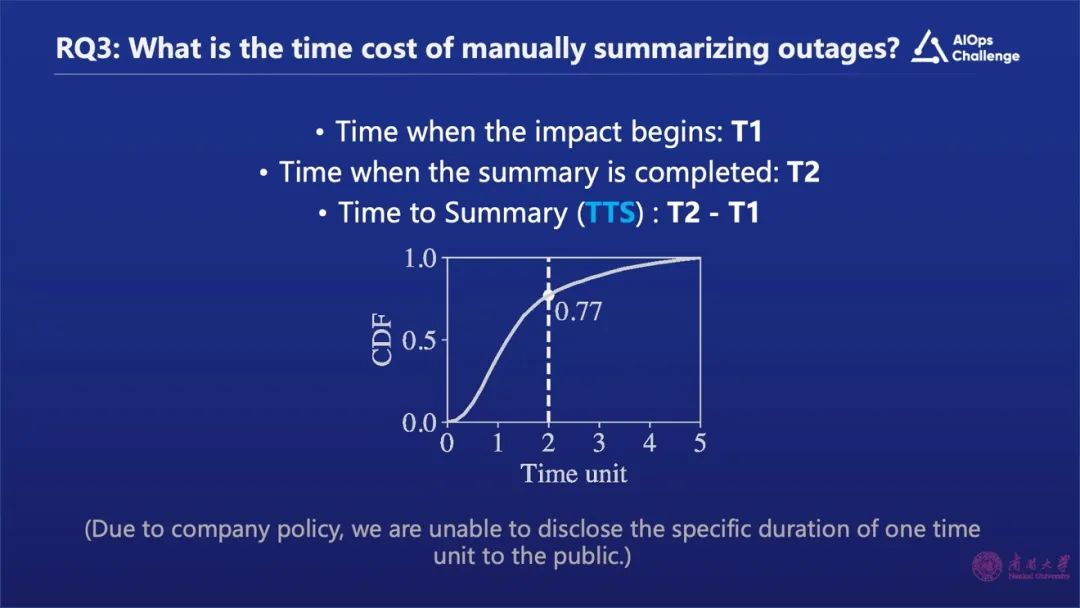
为了解决上述问题,我们利用基于大语言模型设计了一个技术框架,它能够生成一个有用的、可读的故障摘要,大幅降低故障摘要生成时间。什么是有用?指的是能够收集和故障相关且价值比较高的信息,能够很容易的被人看懂,同时还能够大幅的降低生成故障的时间,这也是我们设计这个框架的目标。
整个框架包括几个部分,首先是采集故障相关的告警信息。怎么样去采集?通过三种途径去实现的。首先是基于规则,因为有很多规则可以去利用,比如说一些告警是由同一个指标时间序列异常检测所产生的,那么我们就判定这些告警是相关的。第二是模块,根据历史的告警信息,分析告警与哪些模块是相关联的,那么在新的一次故障产生之后,我们会把与这些模块相关的告警关联起来。第三是深度学习。利用一些深度学习方法,根据语义的相似性,分析哪些告警描述的是同一个事件,那就表明它们是相关的。
我们通过这三种途径,就能够把与这个故障本身相关的那些告警的事件采集起来,构建这个故障的范围。范围确定之后,把范围内全部的告警事件聚合在一块,根据告警的紧要程度进行自动排序。
我们把每个告警的 Title和描述做一个采集,把它们作为一个Context,再把历史上人工所生成的摘要信息作为补充部分,对Chat GPT进行训练。通过这样的方式在新的故障发生之后,只需要把相关告警信息输入进去,就可以生成本次故障的摘要信息。
实验结果
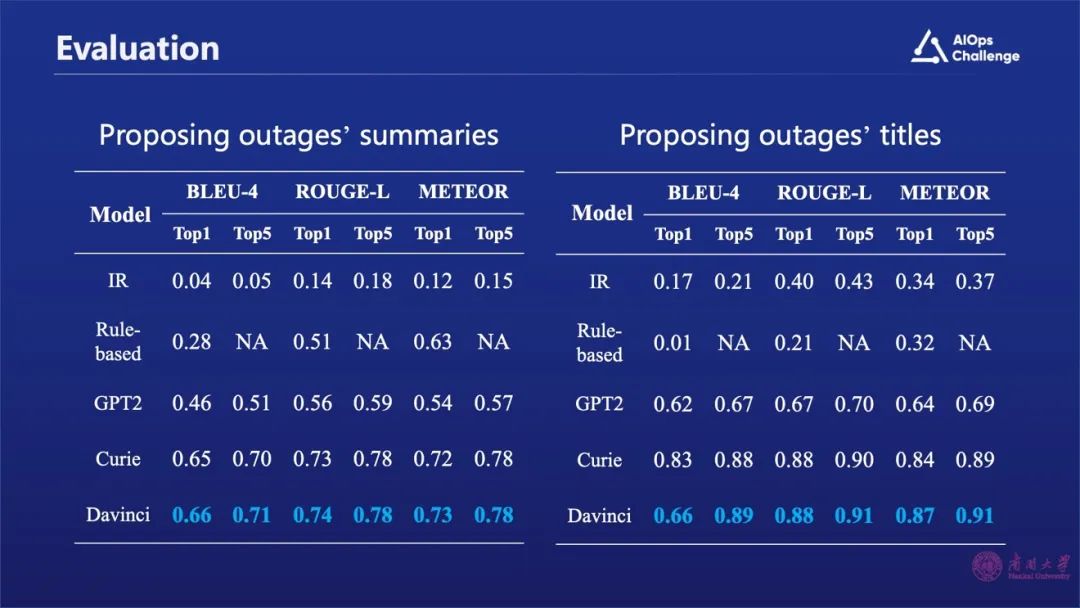
上图中展示的是我们的实验结果,其中Chat GPT3.5在故障摘要生成方面效果显著优于Chat GPT 2和其它规则或检索生成方式。
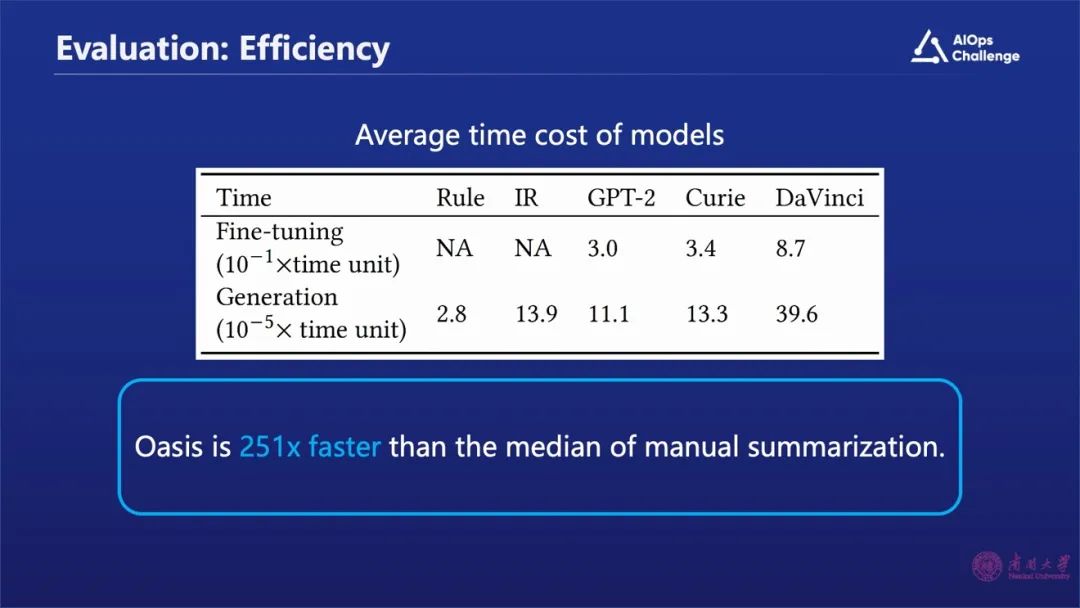
同时,我们发现通过这种方式比传统的人工方式的效率提高了200多倍。
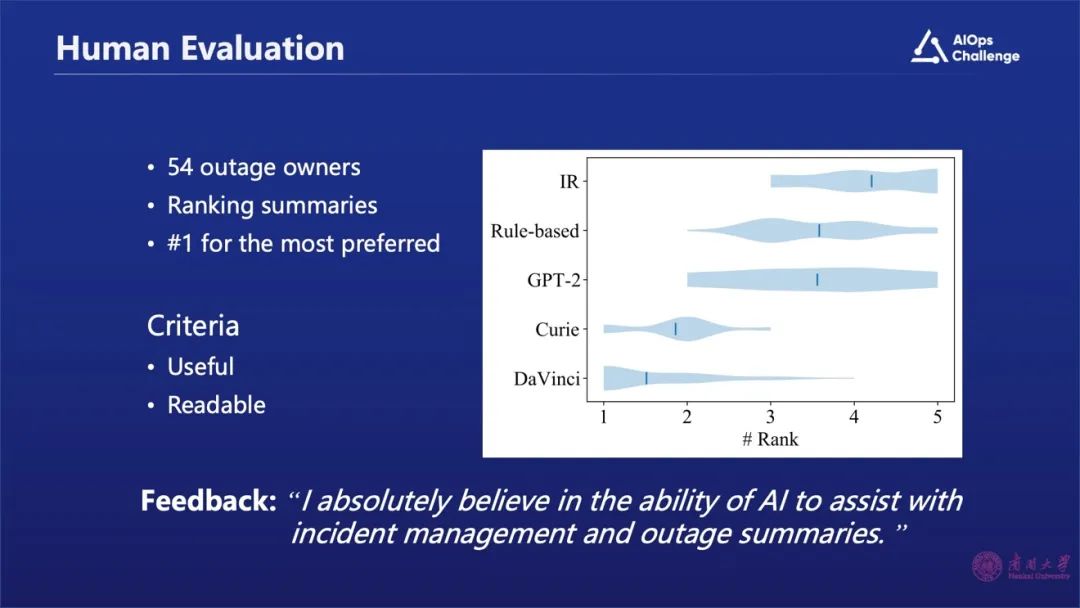
我们还采用了人工的方式,把我们的研究成果发给那些故障的Owner,他们用不同的方法,比如阶段生成或者基于规则来做排序,最后发现大部分工程师都还是会把Chat GPT生成的摘要排在第一位或第二位。
我们还采用了人工的方式,把我们的研究成果发给那些故障的Owner,他们用不同的方法,比如阶段生成或者基于规则来做排序,最后发现大部分工程师都还是会把Chat GPT生成的摘要排在第一位或第二位。
总结

我们的研究首先是对大规模的云服务故障做一个分析;同时设计了一个有用且可读的技术框架,能够大幅降低故障摘要的生成时间;最后我们研究成果得到了微软工程师们的认可,证明该方法确实能够大幅降低故障摘要生成的时间。
以上是我的分享,谢谢大家。