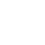运维大模型评测基准OpsEval发布及解读
发布时间:2023-12-25 17:21:00
评测榜单:https://opseval.cstcloud.cn
论文链接:https://arxiv.org/abs/2310.07637
以下文章内容根据中科院计算机网络信息中心副研究员裴昶华的分享整理:
01 为什么会有OpsEval
随着大语言模型的涌现,不光是国内,国外知名的AIOps的厂商也纷纷将大语言模型的知识生成、意图识别和工具编排的能力集成到了智能运维产品中,并提出了自己的基于大模型的运维产品。如知名上市公司DataDog。下图中列举出一些现国外知名智能运维企业他们的产品以及对应的大模型赋能的智能运维场景。

国外各大运维公司提出了自己的大模型赋能的AIOps产品
通过DataDog试用的产品介绍文档可以看出,DataDog的Bits AI能够提供自然语言的交互接口,用户可以通过对话的方式询问当前系统的运行状态,Bits AI会自动分析用户的意图,调用相应的接口,返回对应的系统告警信息。除此之外,Bits AI还能帮助运维人员自动的创建需要的工作流,如回滚操作,单元测试,API测试等。如下图所示:
DataDog的Bits AI产品功能截图示意
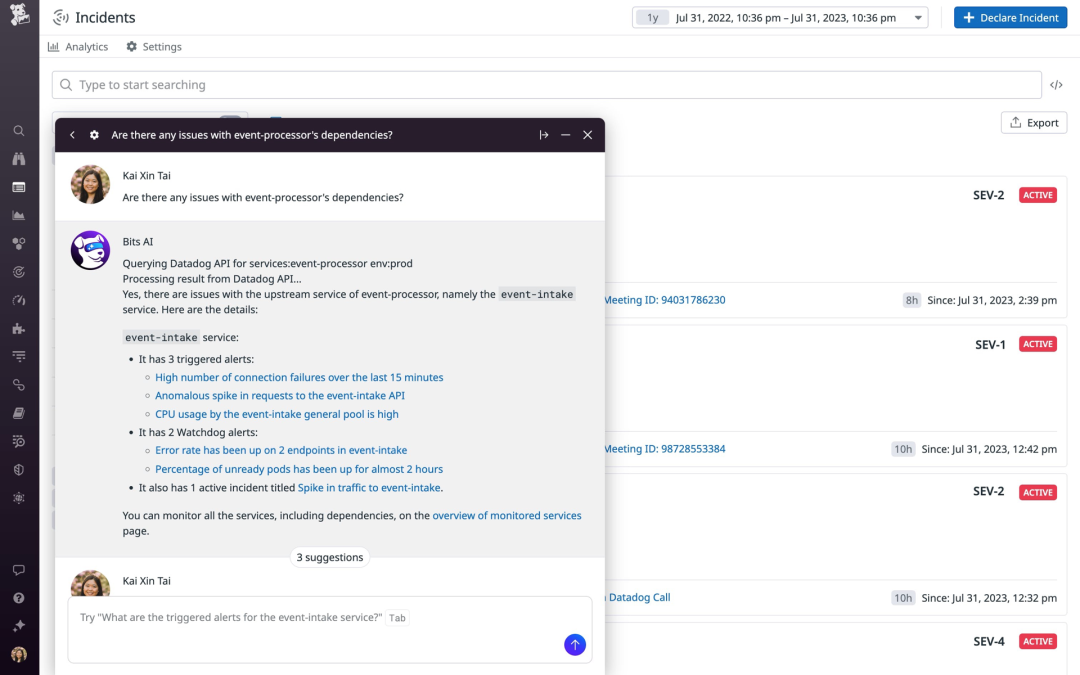
但是真正要大模型应用起来,面临着很多的挑战,不光是训练模型的时候面临的庞大的资源和数据的挑战,在模型选型等方面也面临着非常具体的挑战,如怎么选择适合自己公司的大模型,怎么评测某一次的模型优化是否有效果,怎么向友商或者客户证明自己的智能运维产品的能力等等,都阻碍了大模型在AIOps领域的快速发展。
虽然说这些问题都是AI社区有了部分的解决方案,但是在运维领域却显得难度更大。坊间有个段子:如果家里有矿,就搞通用大模型;家里有数据,就搞行业大模型,家里有理想有场景,就搞Agent智能体。但根据我们和一些业界专家交流,发现国内厂商面临的最普遍的问题是,矿有,数据有,场景有,但是每一样都不是足够充足。尤其是数据,虽然每家公司都有海量的运维数据,但是真正能用作行业模型训练的高质量运维数据非常少,甚至没有足够高质量的评测数据,使得评测结果不够执行。除此之外,现有大模型在AIOps应用还面临着如下的挑战:
由于运维下游场景复杂,不同的公司缺乏沟通交流的通道,无法在第一时间学习到其他先进公司的应用经验;
缺乏一个权威的评测基准,无法评价现有智能运维公司的基于大模型的AIOps能力。
AI社区日新月异,每天都有新的模型和新的技术出现,作为下游垂直应用,怎么选择最实用和最有效的技术方案显得至关重要。
现有AIOps场景下应用大模型的困局
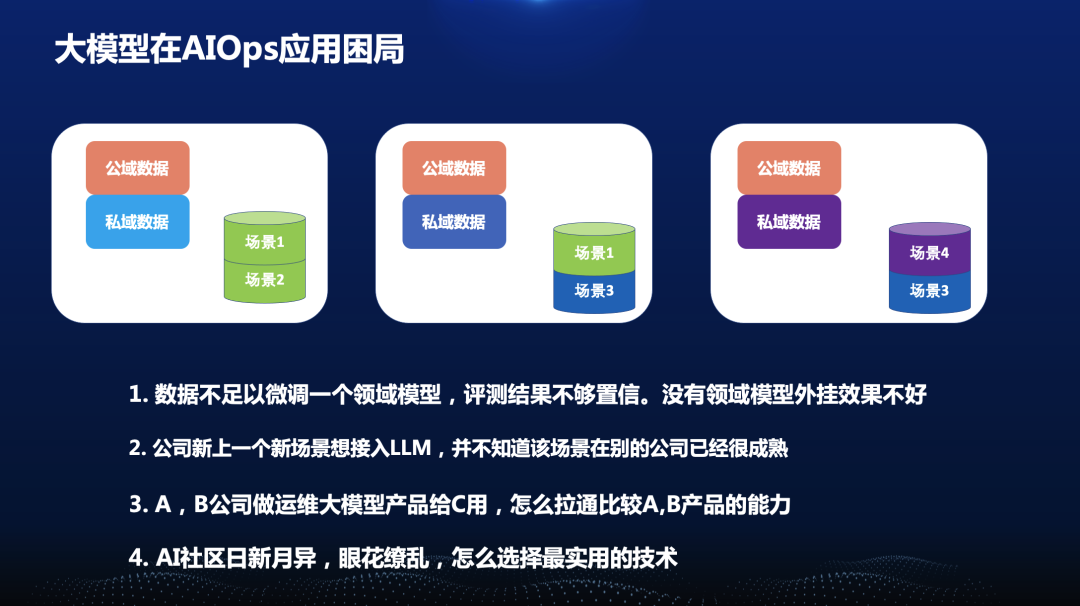
为了解决上述的问题,OpsEval应运而生。OpsEval首先提出了一个基于大模型的通用运维能力评测榜单,将每家单位的公域数据汇聚起来,系统和全面的评测AI社区最新的模型,针对不同的场景任务进行评测,解决大家的燃眉之急。后续OpsEval也会作为Open AIOps Alliance社区的重要功能,持续的为大家提供最新的评测,并定期的为大家提供解读结果。而Open AIOps Alliance社区除了OpsEva评测,还会提供PlayGround,鼓励各大厂商贡献自己的典型应用和场景,社区人员可以在这个基础上读取数据、训练自己的模型、设计自己的智能体代码,在真实场景上应用,平台提供一站式的评测。这些所有的代码、模型和场景都会开源,大家在这个社区中可以像搭积木一样,快速的利用业界的最佳应用提升自己公司的运维能力。
OpsEval在Open AIOps Alliance的位置
02 OpsEval 榜单结果解读
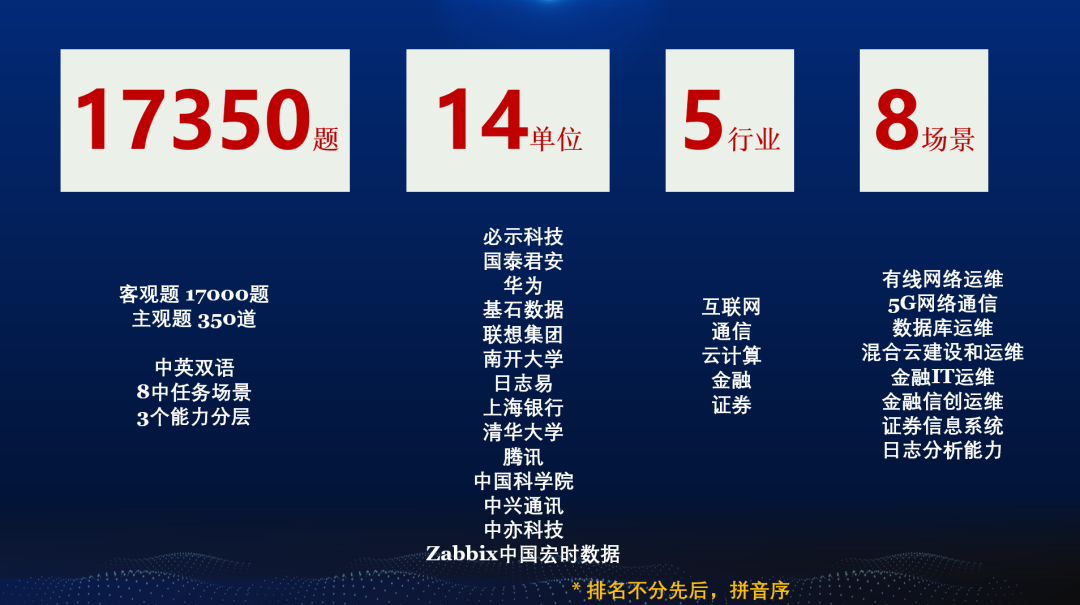
OpsEval第一批参与单位
针对上面所提到的问题,清华大学、中国科学院计算机网络信息中心、南开大学、必示科技、中兴通讯、中亦科技、腾讯、华为、联想、国泰君安证券、基石数据、Zabbix中国宏时数据、日志易等多家首批社区成员单位共同发布了国内首个面向大语言模型的多层次智能运维能力评价基准OpsEval。OpsEval中总共包含17000多道选择题和350道问答题,涉及互联网、通信、云计算、金融、证券等领域,可以对模型的有线网络运维、数据库运维、金融IT运维、日志分析能力等进行评测,应用场景包括5G网络通信、混合云建设和运维、金融信创运维、证券信息系统等。
下面简单介绍一些OpsEval题库中比较典型的,但是大模型回答错的题目并做一个简单的解析。

这个是一个典型的数据库运维的题目,大多数数据库专家可以给出正确的回答。这里备库如果不可用,则可能切换到最大性能模式,此时主库可能会暂停(hang)一个超时的时间。但是在网络上也会存在一些语料写的并不足够准确,从而会误导到大模型。

这个也是一个非常典型的需要领域知识+推理进行解决的问题,Qwen和Alpaca模型没有给出正确的答案,Qwen给的答案是时序数据,如果没有运维领域知识的话大家很容易被这个答案迷惑。事实上,据可观测性理论,telemetry数据中只有日志,trace和metrics,并没有timeseries。
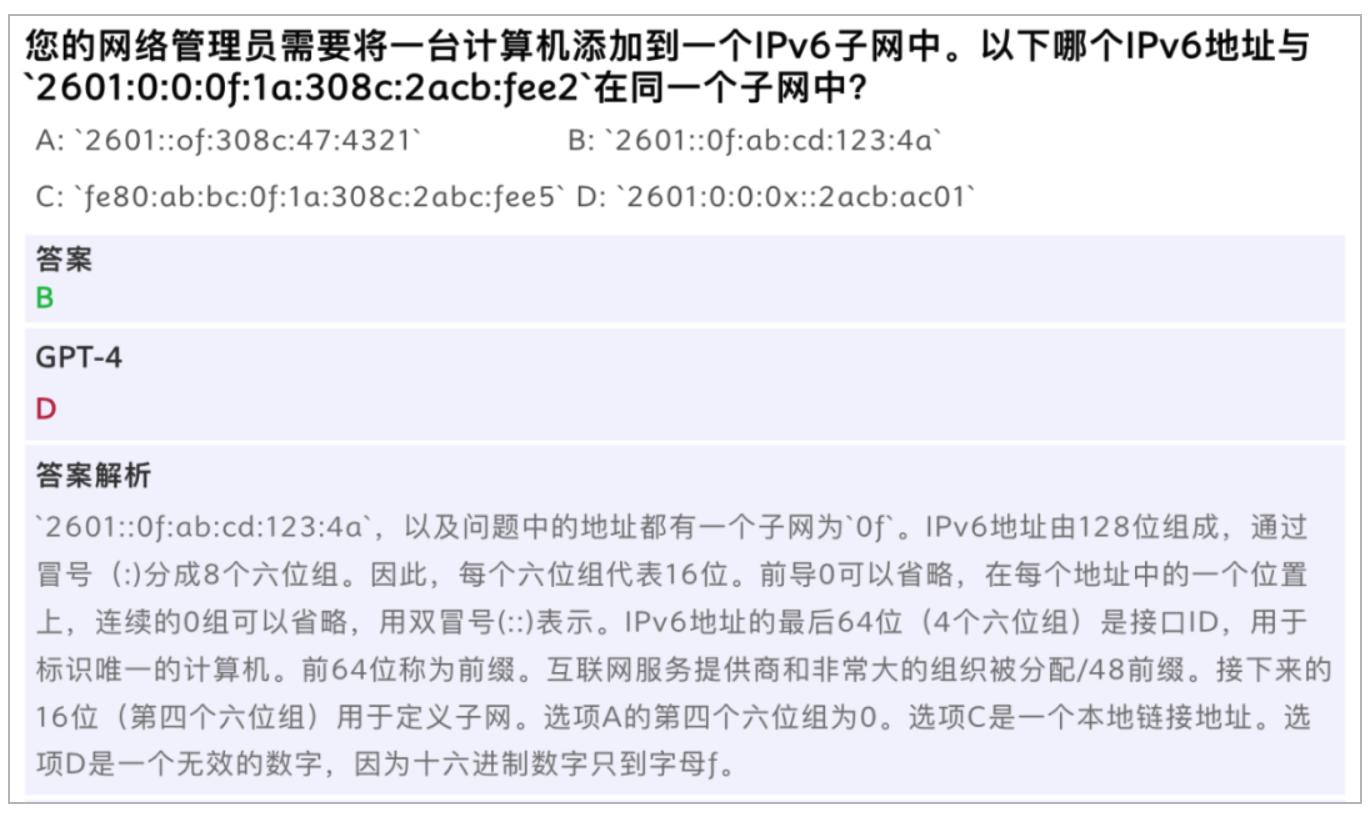
上图显示的问题是一个网络领域的常见问题,对于网络运维专家很容易给出答案,但是大模型对于IP字符不能出现x这种字符的隐形的知识并没有掌握,导致回答的不好。

对于这种较为特定领域的信息,由于缺乏相关的语料等原因,GPT-4无法正确回答。
通过上面的一些典型的问题可以看出来OpsEval中除了一些典型的知识问答,还有较多的需要领域知识和简单推理相结合的题目,而这种能力对于智能运维这种严肃应用非常重要。通过这些问题,我们设计了一系列的评价标准和方法对数十种模型进行了评测。下面对OpsEval的评测结果做一个简单的解读。
Q1: 哪些大语言模型比较有用?
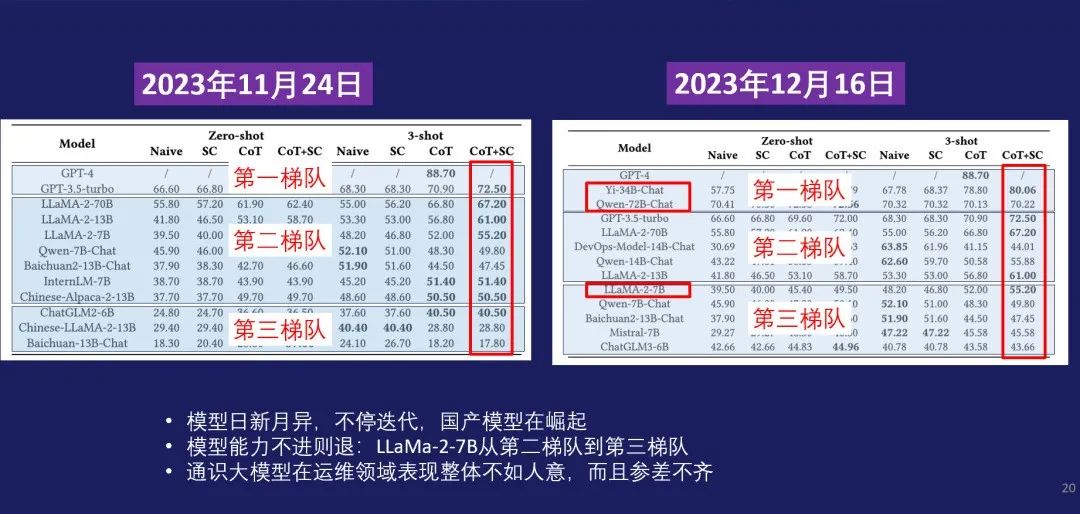
其实大家都很关注目前到底什么模型最好,这里展示的是在11月的时候,这个榜单的评测的结果,右边展示的是12月评测的结果,首先可以看出来这个模型是日新月异,不停迭代。而且可喜的是我们国产的模型在迅速崛起。比如说李开复老师的Yi-34B的模型,Qwen-72B已经超过了GPT-3.5-Turbo。另外我们可以看出模型如果不优化会不进则退,比如说像11月的时候,LLama-2-7B在第二梯队,但到12月它已经掉到第三梯队。另外其实可以看到第二梯队第三梯队的通识模型,整体上来讲的还不是那么令人满意,有很大的提升空间。
Q2: 模型在不同的行业场景下的效果对比
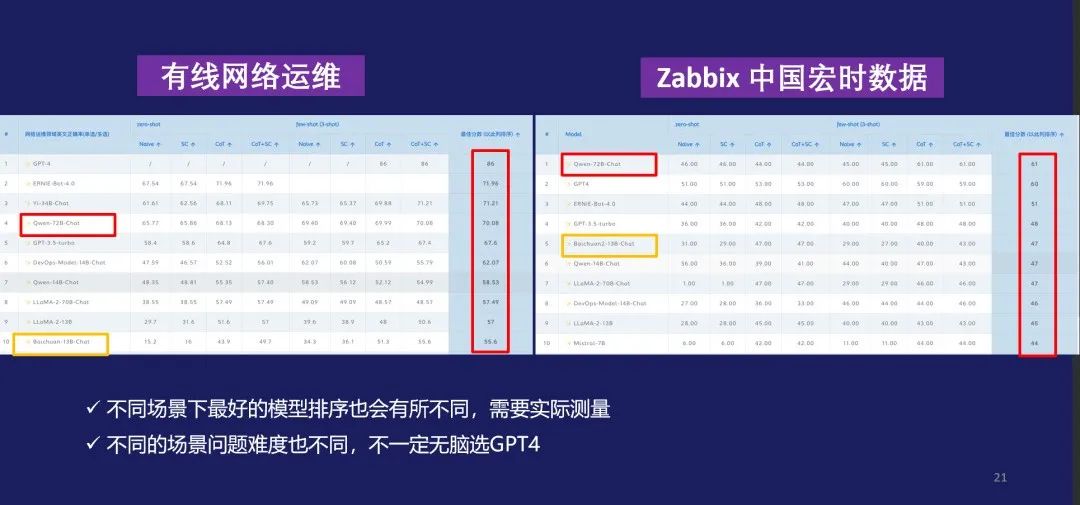
那如果去看在不同场景下的话,它的差距就更大。我们可以看出来在Zabbix提供的评测集合上,最好的甚至都不是GPT-4,像Qwen-72B反而效果最好,这就说明呢,在运维领域,不同的场景需要针对性的实际测评,我们不一定在所有的场景下面都无脑选择GPT-4。
Q3:模型参数量对效果的影响
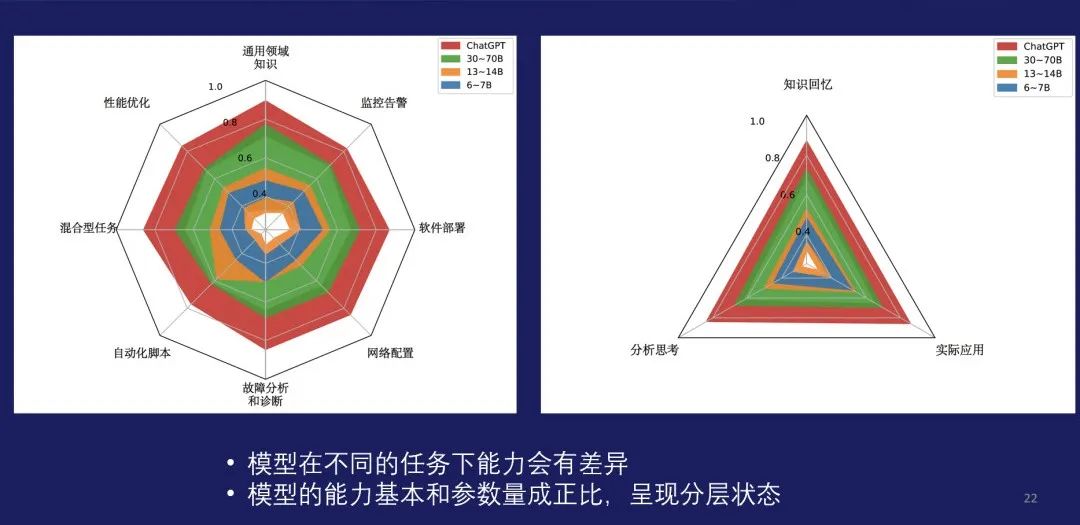
下图中展示了一些不同参数量的模型能力上的区别。从左边的这个不规则的曲线可以看出来,模型在不同的任务上面是有比较大的差异。通过不同的颜色可以看出模型参数量和模型的能力存在一个比较明显的正比的关系,而且呈现一个明显的分层。
Q4: Prompt工程有没有用?
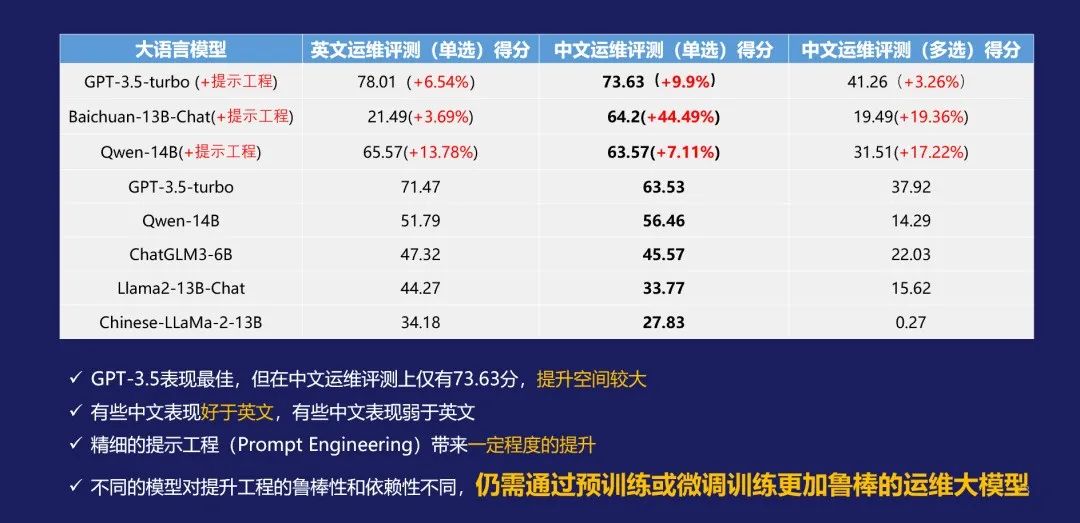
通过评测的数据,也可以看Prompt工程到底有没有用。根据下图可以看出来,是非常有用的,但是对于不同的基准模型,提升的幅度并不相同,仍然需要预训练或微调训练更加鲁棒的运维大模型。
Q5: 怎么评价运维领域问答题?
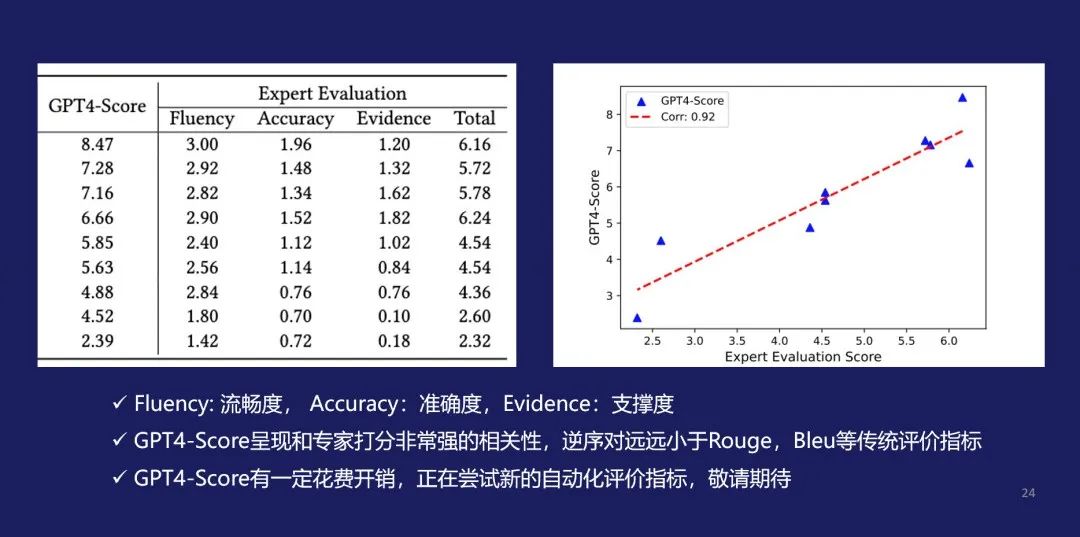
在对模型进行评估时,对于选择题,使用准确性 (Accuracy) 作为指标;而对于主观题,则使用Rouge(对真实答案的召回率), Bleu(生成答案的精确度), GPT4-Score(由GPT4对标准答案和大模型回答进行综合分析打分), Expert Evaluation(由专家根据回答的流畅度、准确性、论据充分度进行打分)等作为评价指标。但是这些指标都需要较多的人力,扩展性不强,我们通过GPT-4来打分,评价模型的答案和参考答案的匹配性,从下图右边可以看出来和专家打分的匹配度还是比较一致的。
Q6: 如何进行模型精度的选择?
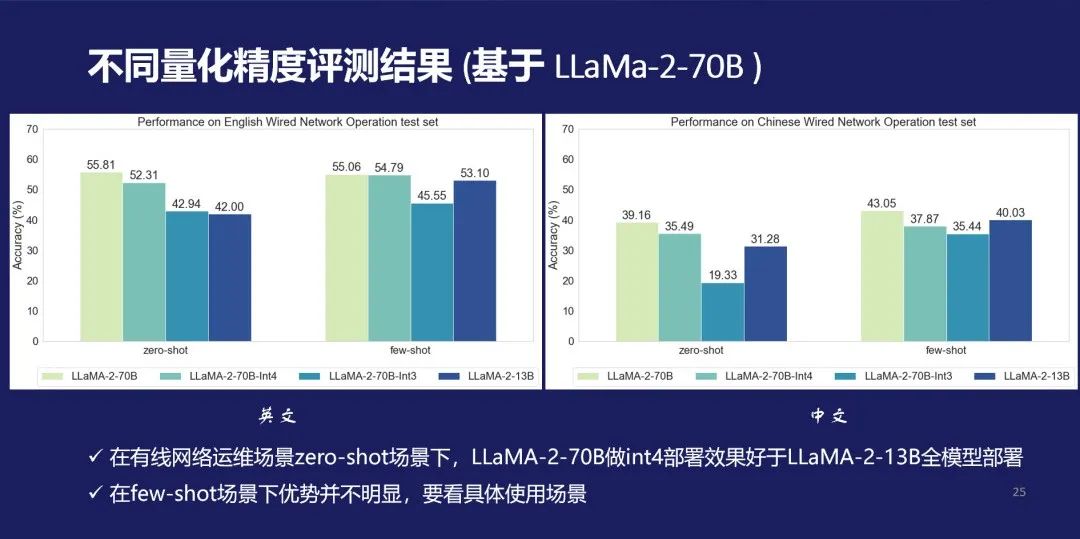
我们在OpsEval中评估了典型模型在不同精度下的表现,如下图所示。可以看出来在有线网络运维场景中,基于 LLaMa-2-70B进行的量化大模型和全量小模型性能的对比。在英文方面,量化大模型的效果要好于全量小模型,few-shot效果则区别不明显。这些结论可以指导我们进行有效的模型精度选择。
03 OpsEval的下一站:Open AIOps Alliance
OpsEval后续会作为重要一环加入到Open AIOps Alliance社区中,为其提供基础“模型 X 评测基准”的排行榜单,同时也会作为后续AIOps挑战赛的平台。我们也将会致力于提出更准确、更易用的评测指标,同时也会汇聚更多的场景的丰富的评测数据,为大家提供第一手的、最及时的、最权威的大模型在AIOps上的能力评测和解读。敬请关注。

Open AIOps Alliance社区定位