清华裴丹 | 运维大模型展望-下篇
发布时间:2023-08-29 17:17:44

2023 CCF国际AIOps挑战赛火热报名中(AIOps挑战赛火热报名中,26万奖金池等你来瓜分!)
上一篇文章我们分享了清华大学裴丹教授演讲的《运维大模型展望》的上半部分(链接:清华裴丹 | 运维大模型展望-上篇),主要讲述了大模型在运维领域应用可能面临的问题和技术挑战、探讨了关于运维大语言模型形态及应用。本篇文章我们会重点分享运维大模型的整体架构和中长期应用。
第二部分:运维大模型整体架构

运维大模型大概是一个什么概念?
首先,要把运维的公域和私域分开。在运维领域共性多于差异化。比如,一个运维专家,从A公司入职到B公司,适应新的工作环境需要一个过程,但是他依靠通用的运维知识也可以快速的展开工作,所以需要把共性的东西集中力量做好。私域方面做一些简化的工作,因为私域很难进行大规模的训练工作,原因是数据出不来,且算力和语料有限。
其次,利用人工智能社区最新、最强有力的开源大语言模型底座,基于多模态的运维知识图谱和混合专家模型,构建运维通用的大语言模型。
第三,需要多模态运维数据的基础模型群。涉及到多模态运维数据的基础模型群,每一项都有典型的、多模态的数据源。就像医学领域一样,需要影像的基础模型、核磁的基础模型、CT的基础模型,每一项都需要深刻地理解它的特点才能够做得更好。直接套用大语言模型处理不是原生的文字语料数据,想要做出好的效果是比较困难的。
第四,运维大模型中还包含已有的自动化的运维工具,通过基础模型的编程框架(LangChain等)编排在一起。前提是这些工具的接口尽量标准化,能够清楚地描述出API,用自然语言描述出来的需求能够直接转换成对接口的调用,不管是简单变成Graph SQL,还是变成配置,或者变成 API 的调用。前提是要做好基础工作,否则参数填错一点点,结果会相差很远。
然后,在私有部署方面,可以使用一些轻量级的方法将私有的个性化特性融入运维大模型中。
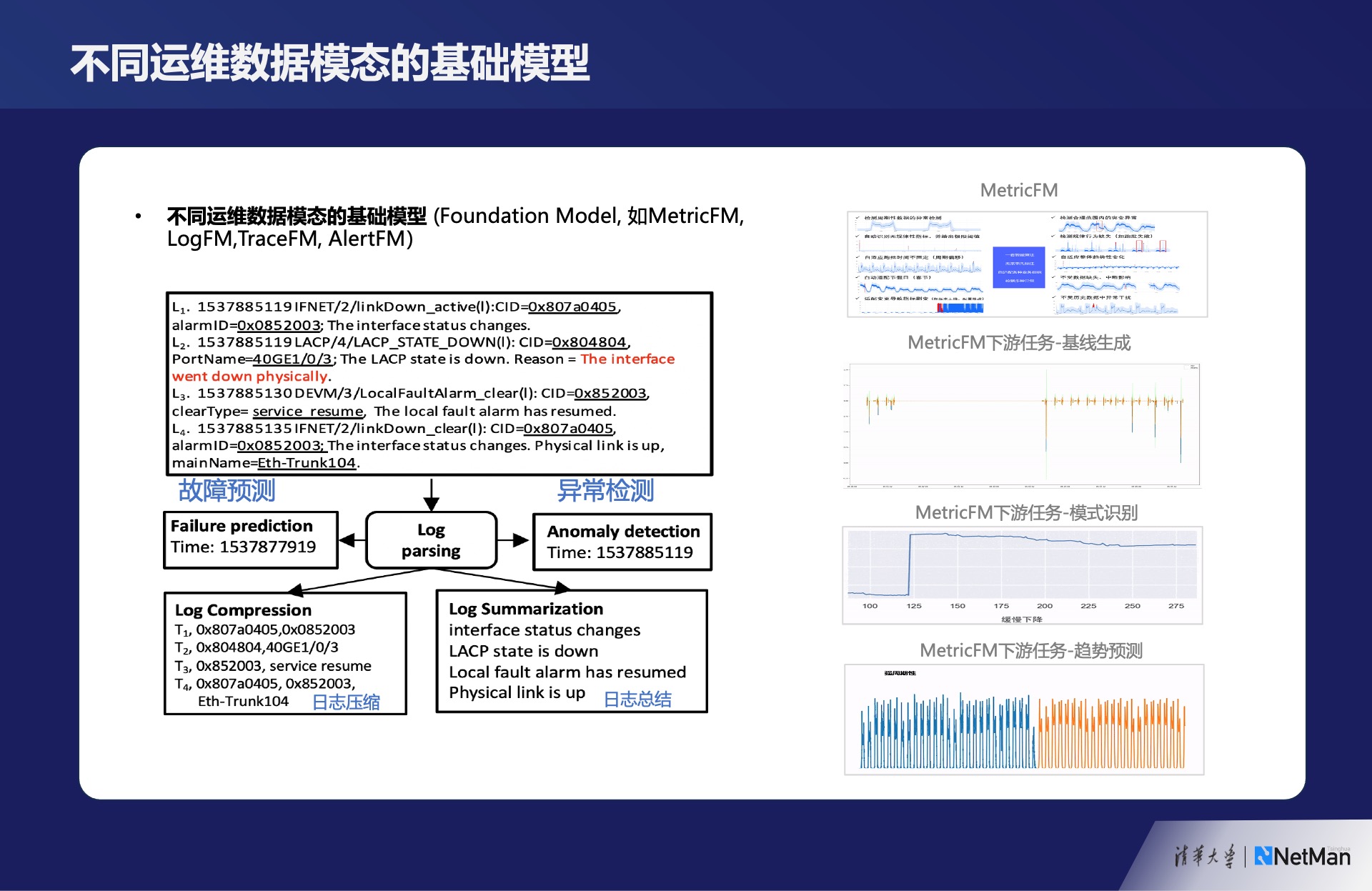
<span style="caret-color: rgb(178, 178, 178); color: rgb(178, 178, 178); font-family: mp-quote, -apple-system-font, BlinkMacSystemFont, " helvetica="" neue",="" "pingfang="" sc",="" "hiragino="" sans="" gb",="" "microsoft="" yahei="" ui",="" yahei",="" arial,="" sans-serif;="" font-size:="" 13px;="" font-style:="" normal;="" font-variant-caps:="" font-weight:="" 400;="" letter-spacing:="" 0.44200000166893005px;="" orphans:="" auto;="" text-align:="" center;="" text-indent:="" 0px;="" text-transform:="" none;="" white-space:="" widows:="" word-spacing:="" -webkit-text-size-adjust:="" -webkit-text-stroke-width:="" background-color:="" rgb(255,="" 255,="" 255);="" text-decoration:="" display:="" inline="" !important;="" float:="" none;"="">MetricFM
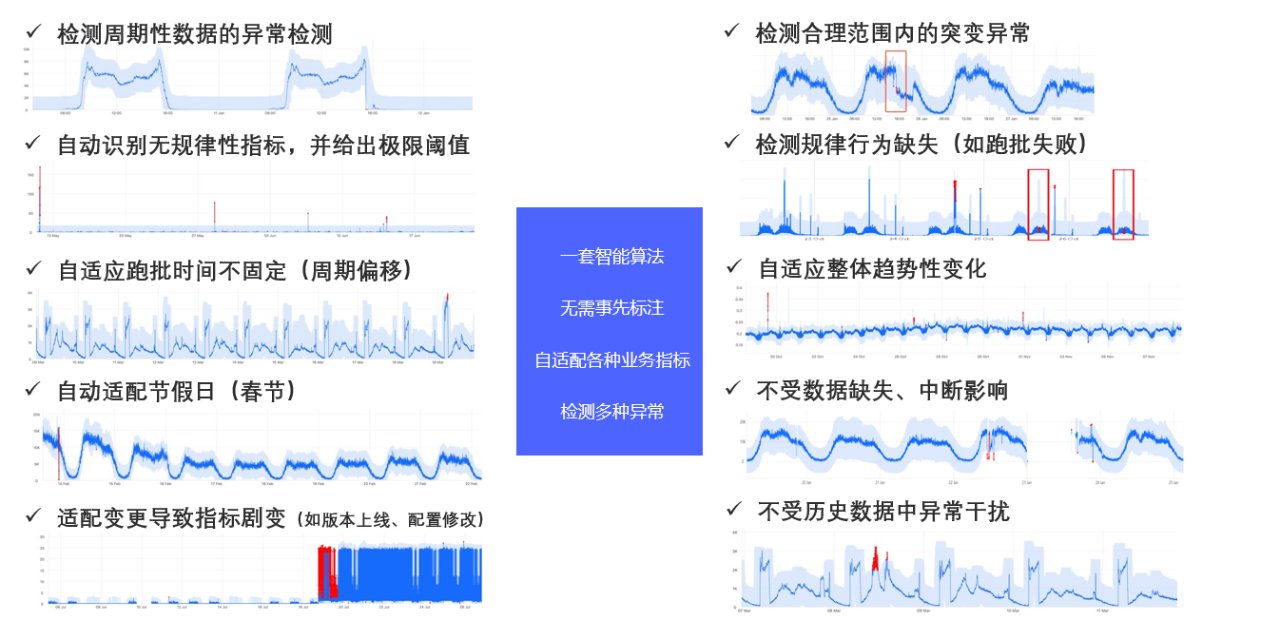
运维多模态的数据,如最常见的监控中的指标数据,它的形态是多样化的,不同的指标形态不一样,有些业务指标跟人的作息相关,周期性很强;有一些偏基础设施,规律性较弱。
基于这些指标,会有很多任务,比如说监控,用算法动态计算上下波动的基线。上图是我们演示的效果,需要针对不同模式计算出基线,其本质是捕获指标数据内在规律的一种能力。
比如说现在的任务不是计算一个上下波动的基线并产生告警,而是要识别出来现在有哪些模式:是爬坡、是上台阶还是下坡,这其实是对模式的一种捕获能力。
比如趋势预测,计算它的斜率是向上还是向下,算斜率的时候,这个曲线不一定是直线,可能是有一定的趋势又带一定的波动。
过去我们用小模型的方式,每一个都是单独做模型,然后评估准确率。本质上需要对底层类型的数据有深刻理解的能力,在这之上建立基础模型,而这些任务就是基础模型的一个个小模型的应用。对于日志、trace数据、告警数据、其他数据也都是类似的情况。多模态的数据每一个都有自己强烈的特点,基于这些特点建立的基础模型(Foundation Model),然后对它的上游应用再建立模型,这种思路对AIOps智能运维方向也是一个不错的启示。
过去,我们可能在小模型上进行了许多尝试,现在大语言模型在“文字模态”的数据下取得了如此好的进展,这也为我们在智能运维方向上使用多模态运维数据的基础模型提供了更多信心。

从架构的角度来看,我们面临一个不可避免的问题:开源大模型层出不穷,那么应该选择哪个模型、哪个底座呢?如果一个月后所选的已不再是最新、最强有力的,该怎么办?
上图中显示的是6月30日排名靠前的模型,但现在已经被大幅更新了。大模型快速发展给了我们信心,当前的计算效率问题、能力问题以及模型规模问题都将逐渐被AI开源社区解决。全球最聪明的AI专家们都被调动起来,共同朝着一个方向努力,所有问题都将逐一解决。包括私有部署的算力问题也将得到解决,可能不会那么快,但我们应相信开源协作的力量。
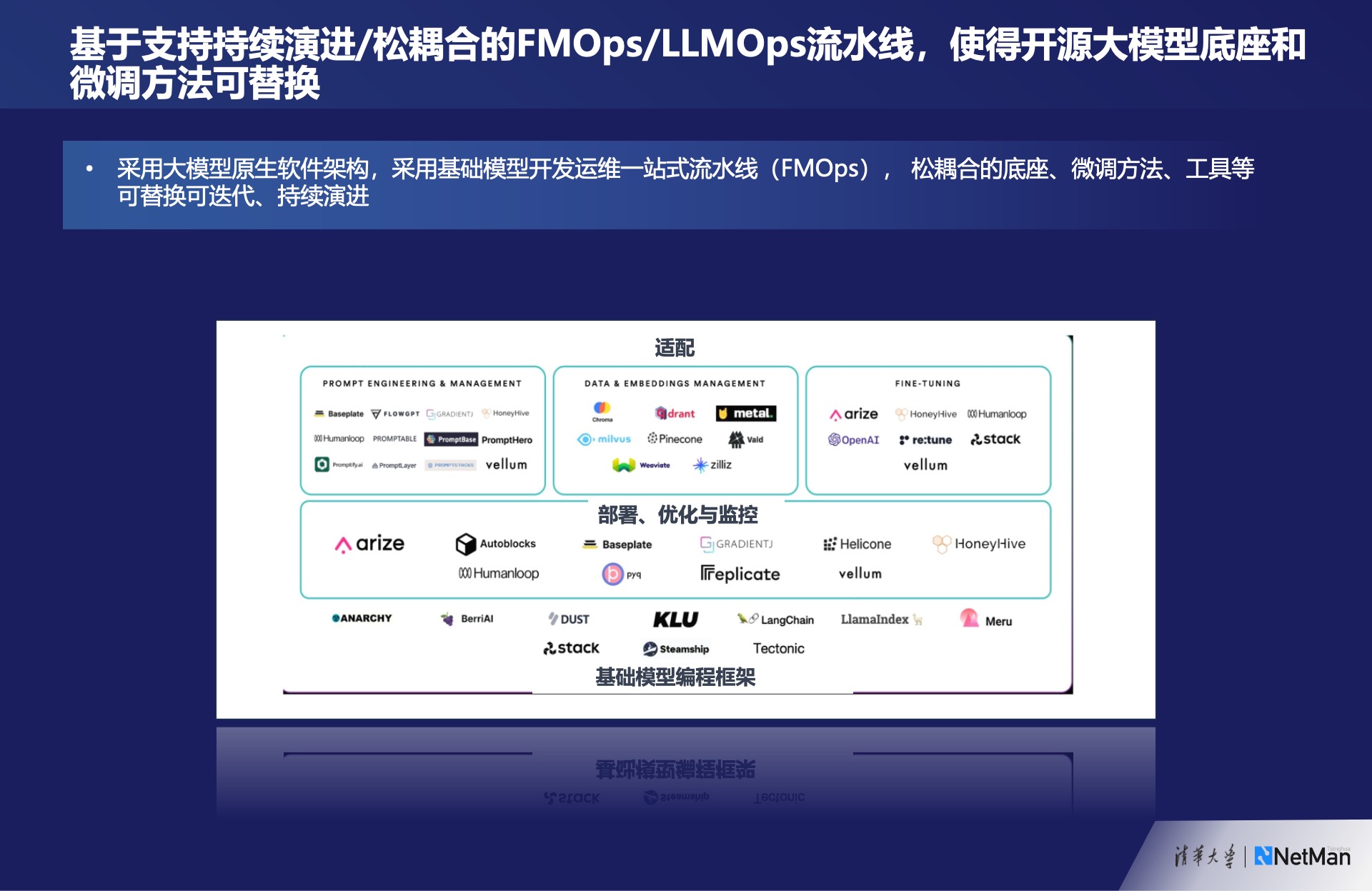
同时,我们都非常担心被某个模型或方法所束缚。上图展示了大语言模型的基本框架,包括适配、部署、优化和监控,以及基础模型的编程框架。类似于DevOps的流水线一样,我们尽量使每个部分都可替换和松耦合,这样在某个组件更新时可以直接替换。底座、微调方法、各种工具等都力求可替换,以便在工具演进过程中能更好地利用开源社区的最新成果。
第三部分:运维大模型中长期应用

假以时日,运维大模型将来能有哪些应用呢?
某些规模庞大的机构,如果拥有充足的语料和算力资源,实际上可以进行类似私域微调的工作。微软曾发表过相应的论文,基于其公有云上大量的工单数据,利用机器自动生成工单。经过评估,机器生成的工单与人工书写的工单非常接近。说明机器具备这样的能力,但这涉及到语料的质量和数量方面的要求。
例如,根据历史工单信息给出故障定位、故障止损建议和相似故障提示,提供与历史故障的相似性比较以及当时的止损方法等,可能对我们正在发生的故障止损提供重要的提示和帮助作用。
此外,还包括当大量的告警发生时,由机器为这些告警信息生成告警摘要。类似一大段文字由机器进行文字摘要一样,这里针对的是正在发生的故障产生的一堆告警信息,甚至是告警风暴,由机器产生告警摘要。
总之,凡是涉及文字相关的内容,都可以在这方面进行相关的应用尝试。当然并不一定每个机构都具备这样的语料和算力资源。
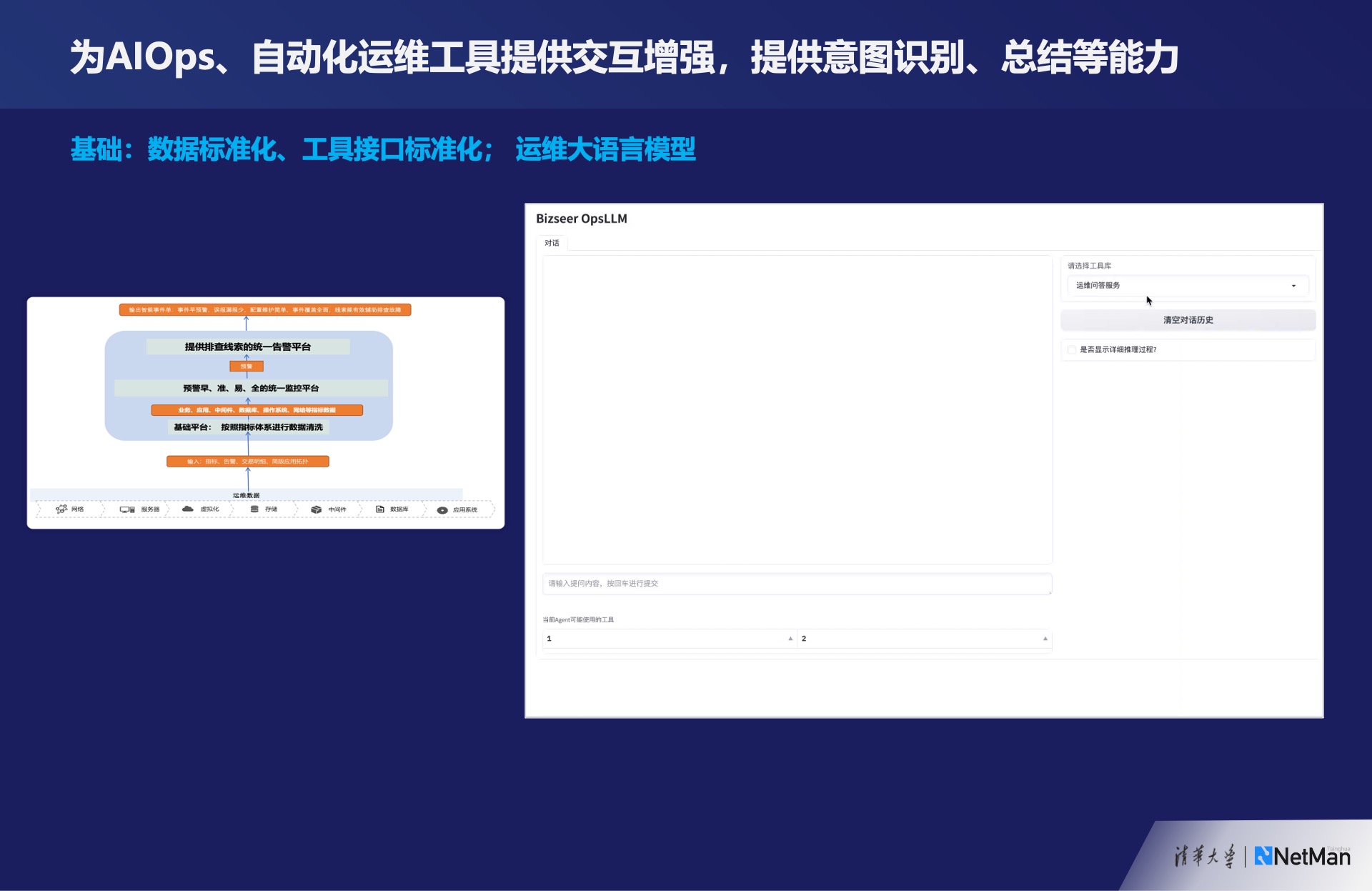
为已有的智能运维工具和自动化工具提供交互增强。交互增强指的是从文字角度的意图识别和结果总结能力。举例来说,某款工具导入了所有的监控数据后可以进行各种风险告警、故障告警,从监控数据到自动建单,并给出根因分析结果。如果在最外层加入基于大语言模型的输入输出的增强,这个工具的便捷性和受欢迎程度将大大提升,前提是需要进行一些数据处理和接口标准化的工作。这是对单个运维工具进行提升的方法。
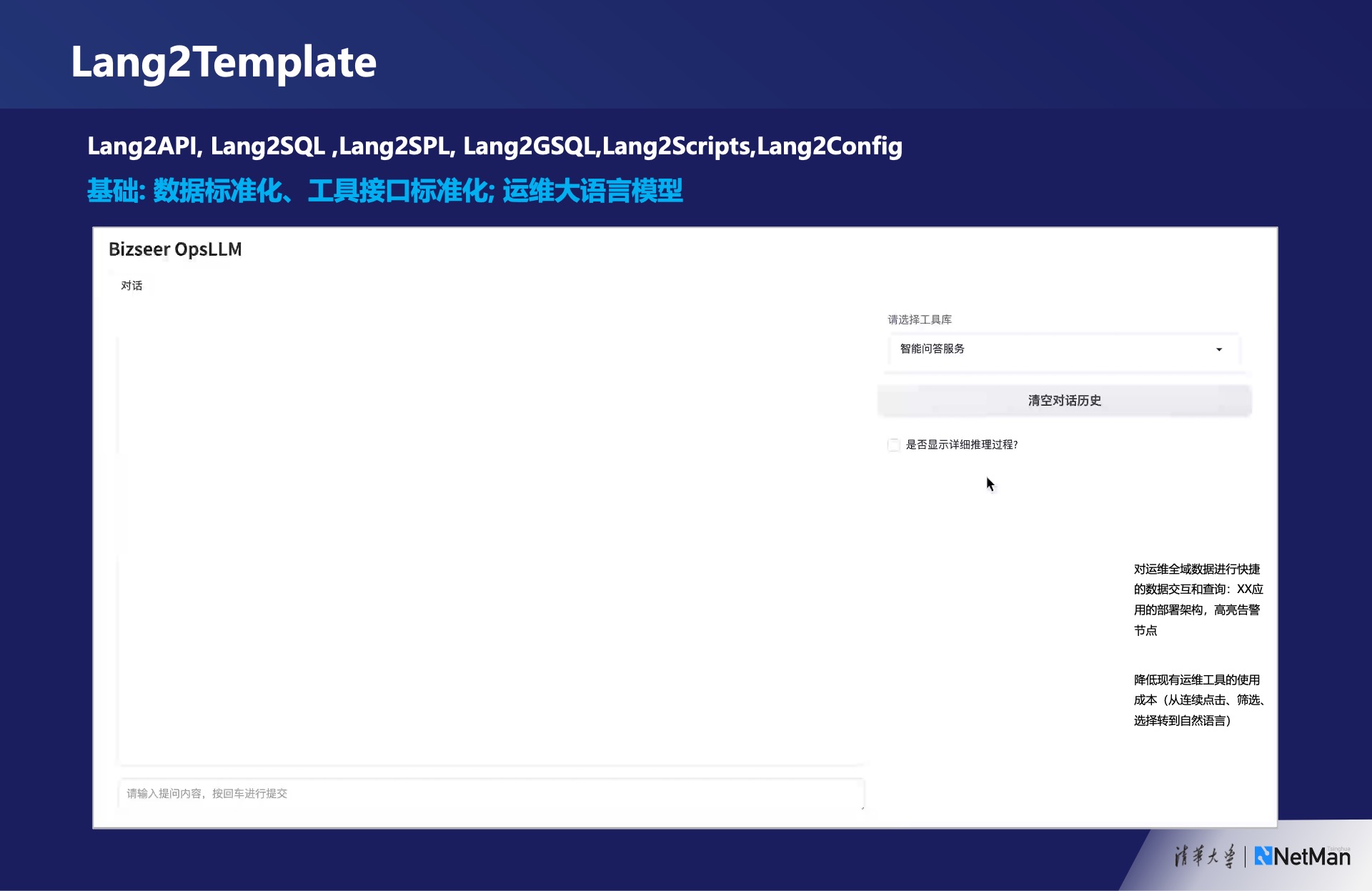
在许多情况下,我们需要将自然语言转化为模板(Lang2Template),这个模板可能是通过自然语言表达出来的对数据库的查询,然后自动生成相应的SQL语句。类似的,我们也可以将自然语言转化为Splunk查询语句,因为像Elasticsearch和Splunk等工具都提供了用自然语言表达日志数据查询的功能,并且可以进行图形化展示。
除此之外,我们还可以使用自然语言表达图数据库的查询,并自动生成配置和脚本。这与自动化生成代码的过程相似,只是在运维领域中,我们经常使用脚本来自动调用各种API。因此,利用自然语言表达的模块包含哪些服务的信息,我们可以生成一个图数据库查询,相当于是一个拓扑的模块调用的关系存在图数据库里,然后用图数据库中进行自动生成的图形和SQL。

假如现在要实现一个相对复杂的任务和场景,如出了一个故障,需要查询这个应用下面所有组件的所有的监控数据,而应用下面可能是上图中的一个拓扑图,有许多组件,每个组件上面既有日志数据,又有指标数据,还有其他数据。
首先去图数据库里边生成一个Graph SQL,把这个节点的数据拿出来,然后再拿这节点的信息去挖取不同的指标数据库、日志数据库,再去查对应的数据。可以想象一下其实就是用类似LangChain的工具,把刚才这一系列操作串联起来。所有已有的运维的工具,接口定义清楚,数据基础良好,就是一个有效的编排的工具,可以跟各种已有的运维工具进行交互,把结果使用更容易理解和接受的自然语言反馈给用户。
这里回答下前面我提出的问题:运维大语言模型与AIOps的关系是什么?可以认为大语言模型是实现AIOps的必要和有效的一种手段,同时跟已有的工具可以对接可以互补的一个关系。

目前我的主要的观点总结成这样的一幅架构图。
运维大模型是一个融合的模型,它涵盖如下几个部分:
首先,运维大语言模型(懂运维的大语言模型)是整个架构的核心基础。
其次,在架构上区分公域和私域的运维能力,公域的部分尽量做好,私域部分也尽量不依赖于那些质量、标准化程度、数量参差不齐的问题。
运维大语言模型:里面包含运维的知识图谱、混合的专家模型和开源的大语言模型的底座。底座部分尽量松耦合一些,借助流水线的工具,从而达到可替换可迭代、持续演进。多模态基础模型群:运维数据是多模态的,目前的大语言模型的效果还有待改进,如果我们想充分利用大模型的能力,可以在每一种模态的数据里面做基础模型,比如我们在日志方面已经做了基于transformers的架构,在指标方面基于transformers的架构做一些基础模型的尝试。基础模型编程框架:基于编程框架能够把这些已有的工具和新的工具串联在一起,更好地实现运维场景的智能化。
关于运维大模型应用,运维专家知识的问答可能是最直接的一个应用,基于上述能力和工具,再外挂一些知识就能直接使用。不用对接实时的监控数据,也不用考虑监控数据的质量问题,这是一个短期内可以落地的应用。
我们还可以基于相对丰富的私域语料做一些尝试、单个运维工具的交互增强也是可以尝试的,前提是我们运维大语言模型进化到一定程度,然后从自然语言到各种模板API的调用(Lang2Template),最终用基础的编程框架(LangChain/APIChain等)对经典运维工具进行编排调用,完成更复杂运维任务。
这是我目前对运维大模型的一些理解,谢谢大家。