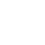IDC创新奖|光大证券智能运维平台
发布时间:2022-11-14 10:48:00
智能运维作为支撑金融机构数字化业务稳定持续运行的关键手段,在金融领域应用已成为刚需。银行、保险、证券等金融机构正加速建设智能运维体系。光大证券作为国内重视金融科技投入的头部券商,其智能运维平台项目荣获“2022 IDC中国金融行业技术应用场景创新奖”,作为此AIOps智能运维平台建设的合作伙伴,必示科技与光大证券携手为同行及更多金融机构开启智能运维建设树立了行业标杆,为金融机构运维走向智能化提供发展范式。

必示科技携手国泰君安共同举办的第五届双态IT乌镇用户大会智能运维算法研讨会上,光大证券运维开发工程师杨启锐分享了智能运维平台建设整体概况和平台架构,本文根据演讲内容整理而成。

近年来,伴随证券业务系统频繁升级、系统数量增加、系统交互关系日益复杂,IT系统的安全稳定运行面临着巨大挑战。光大证券以“赋能监管控运维体系,提升运维效率和系统可用性,降低MTTR,提升用户体验,降低运维系统建设成本”为建设目标,以场景驱动为核心,构建多层次、精细化的智能运维模式,实现对故障预警和根因定位的主动感知,及时消除发生重大故障的潜在风险。
光大证券智能运维平台建设分为四个阶段:2017年,升级监管控运维工具和大数据平台,启动智能运维平台建设;2018年建立统一日志管理体系,形成日志采集、存储、检索、可视化能力,并同步建设CMDB;2018年至2020年与必示科技合作,引进智能运维算法,通过指标检测和数据分析,实现准确故障发现和快速故障定位;2020年至今,场景持续细化建设,深化探索故障定位场景,已覆盖核心交易和业务办理场景。未来将持续建设更多智能化分析能力,覆盖更广泛的业务场景。
智能运维平台以运维数据工厂和运维知识图谱为基础,统一构建故障发现与故障定位等上层AIOps场景。系统层是平台的基础,涵盖各种数据源;其上通过数据总线实现各类数据缓存和交换;数据处理层由算法、数据存储和计算等模块构成。其中智能分析能力涉及时序指标异常检测、关联分析、聚类分析等多种算法,大数据平台则提供数据计算和数据存储能力。通过CLICKHOUSE将所有交易明细数据实时接入到平台中,增加数据分析时效性。其上是统一接口层,负责平台上下层服务间的接口调用。AIOps场景层的建设重点在于异常发现和快速定位,目前在探索故障预测场景。
整个平台采用开放式架构,综合智能算法、微服务、数据总线,实现服务接口和各类数据的模块化组织,快速迭代去建设新的运维场景。
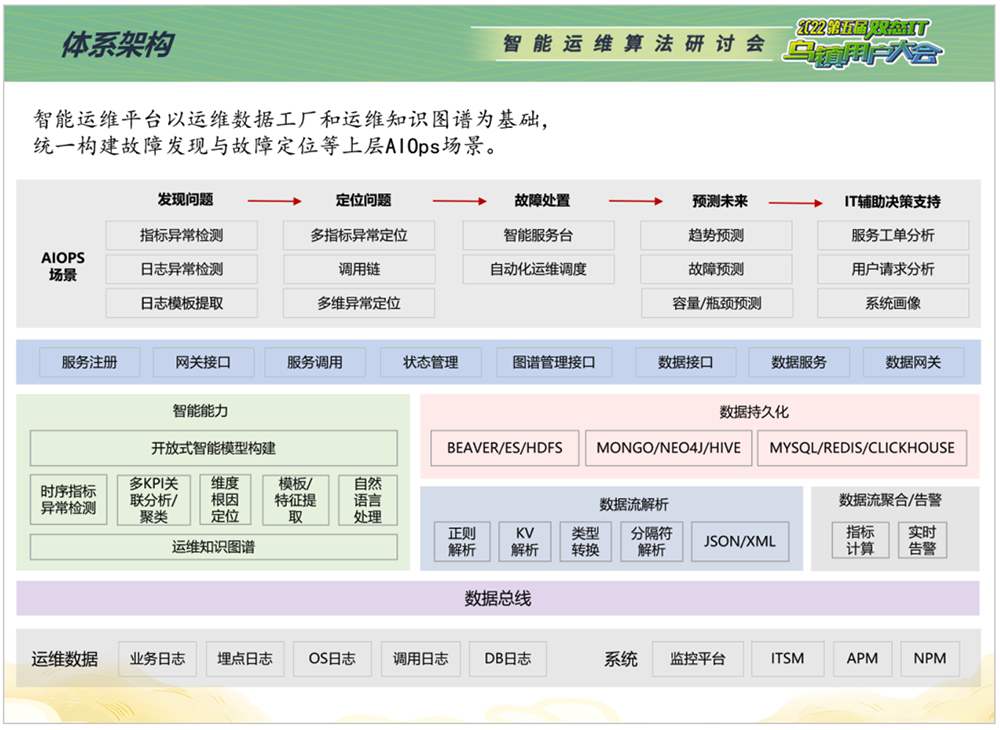
智能运维场景建设主要是运用机器学习算法,对海量运维数据进行挖掘分析,从而提升异常检测与故障定位的能力。
应用系统层。包括功能号级业务指标的异常检测场景,以及运行日志的异常检测场景,检测到指标异常后会自动触发对业务多维指标的分析定位,判断异常原因所在的维度。对于调用关系复杂的多系统场景,调用链根源系统定位能够判断出哪些端口或者服务有异常。
基础设施层。有些业务指标异常可能是由基础设施层引起,当平台检测到业务指标异常后,将自动触发对上述业务所依赖的基础设施对象进行定位。基础设施对象包括主机、数据库、存储、网络等。例如针对数据库的核心指标进行异常检测,同时接入数据库日志、传统数据库检测工具的告警,就可以快速定位到数据库引起的异常。网络、主机和存储同样可以运用算法对指标和日志的运维数据进行检测。
海量运维数据支撑智能运维平台的整体建设,以业务明细多维定位、机器指标定位为核心场景是平台持续建设的重点。
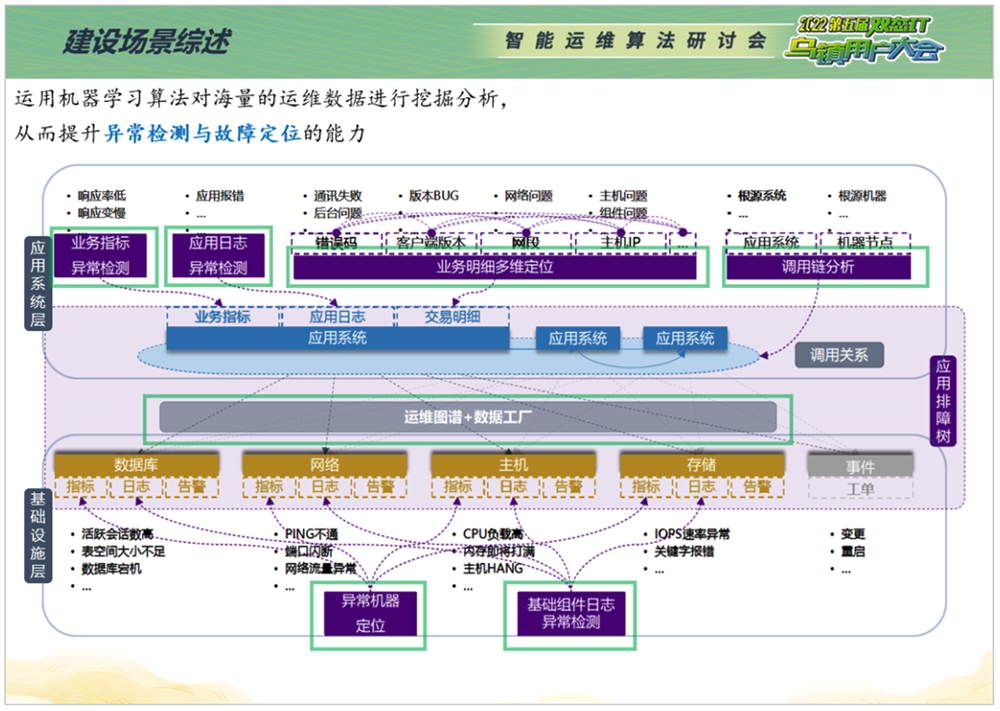
业务指标异常检测。衡量业务系统稳定性或者服务质量通常有很多关键指标,比如成功率、调用次数等,对这类直接反映业务运行可用状态的黄金指标进行异常检测有助于及时发现异常,为后续的诊断分析和修复赢得宝贵时间。
传统采用静态阈值的方式,配置工作量大,易漏报误报。以功能号为例,需要对不同时间段都设置合适的阈值,才能最大限度保证阈值准确性。但往往网交系统可能会有1000多个功能号、4000多个不同的指标,传统静态阈值的监控方式由于存在无法适应业务指标波动、阈值设置不准确、阈值配置工作量大、无法适应特殊日波动等明显缺点,很难达到理想的监控效果。
相比之下,借助AIOps智能算法全自动适配大规模业务指标、无需人工标注和干预、自动检测多种异常的方式,能够给业务可用性监控带来巨大裨益。
业务指标异常检测使用特征描述器接入数据,判断数据是否具有周期性、趋势性、抖动程度等特征,根据这些特征自动选择算法或者算法组合进行异常检测。检测结果可以识别多种规律,比如一些周期性强、有规律的数据,业务指标异常检测能够适配版本上线、变更导致的指标剧变,检测合理范围内的突变异常,检测规律行为缺失,自动识别无规律性指标并给出极限阈值,不受数据缺失、中断的影响。
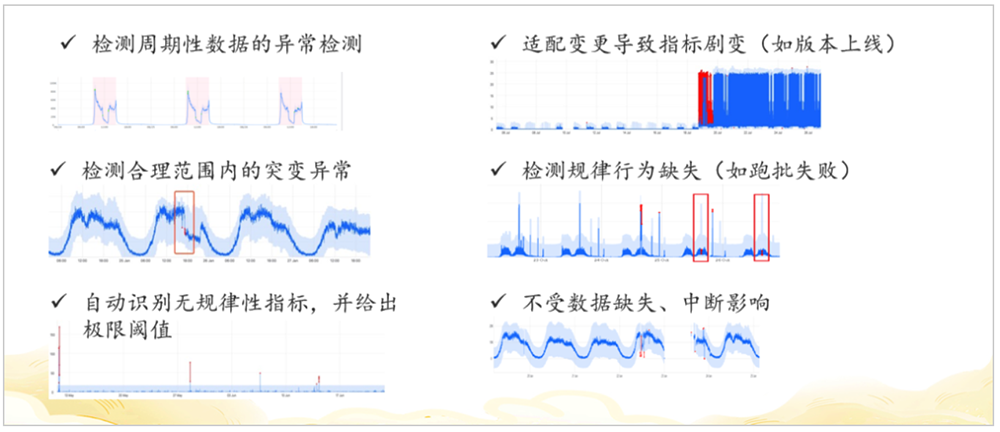
对业务指标异常检测的结果做进一步挖掘,需要用到业务明细多维定位。当网交响应时间在某一个平均时间内增加,是操作系统出现问题,还是某个版本的网交在某个城市出现了问题?是不是通过某个返回码的用户会出现同样情况?这时会涉及到较多维度的分析,传统解决方式是首先对功能号、客户账号、IP等交易明细进行解析,再按照经验对不同维度进行聚合,计算出每一个取值的平均响应时间和交易量。但这种方式无法一次性得到结果,需要对不同组合不同维度进行多次聚合,导致运维管理员无法快速响应告警并定位到异常维度。这时,业务明细多维定位的价值和意义就凸显出来了。
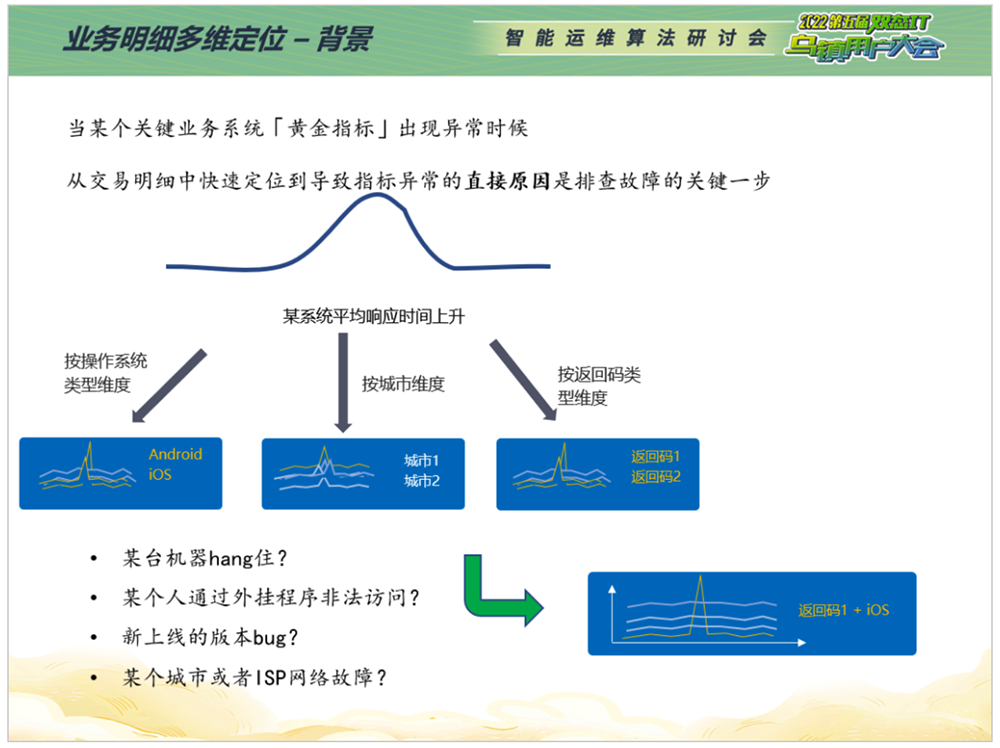
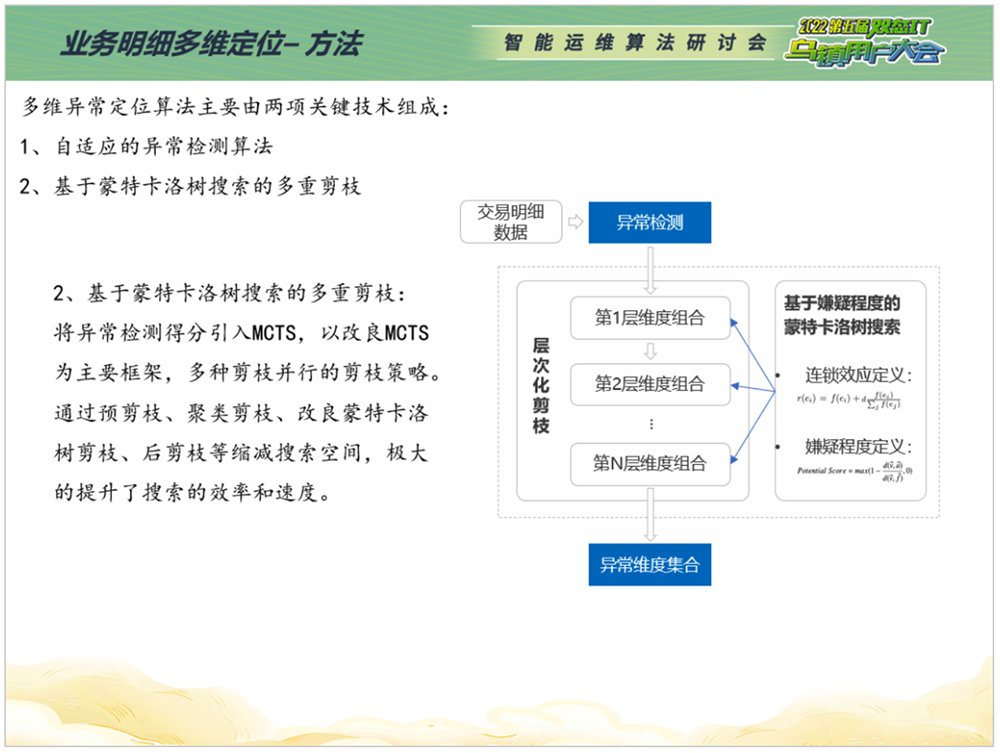
业务明细多维定位由两项关键技术组成:
基于影响力的自适应异常检测算法,判断哪个维度或者哪个维度组合对整体指标的变化影响最深;
基于蒙特卡洛树搜索的多重剪枝,提高搜索的效率和速度。
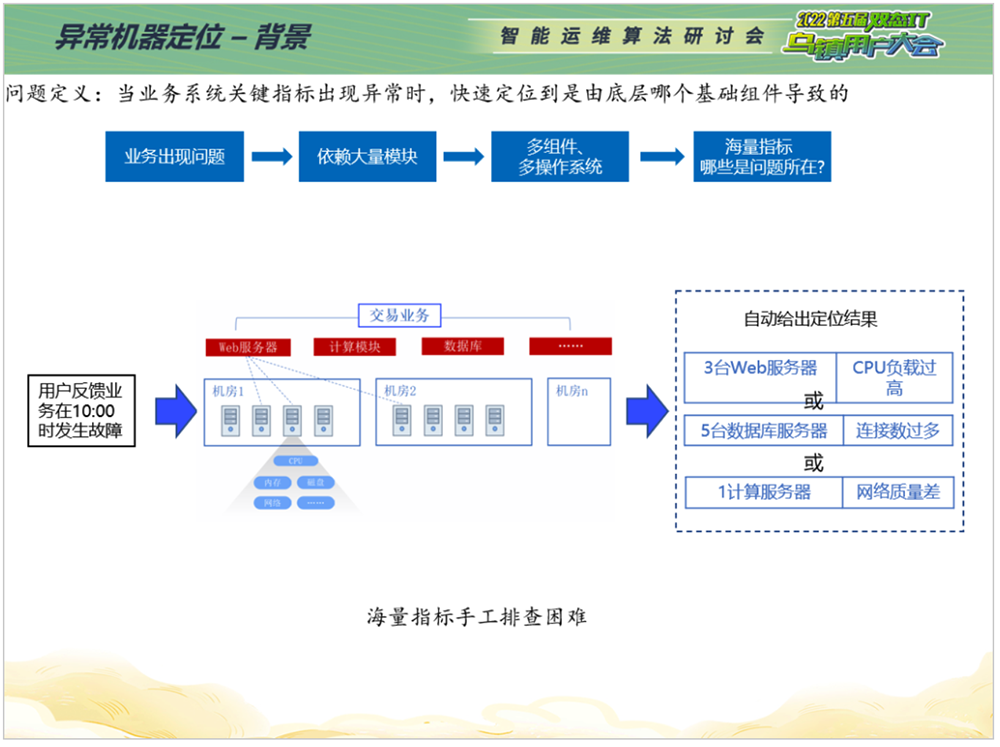
机器指标定位。很多业务性能指标的变化是由机器异常引起的,或者说机器指标也有直接体现。比如某个分布式应用的业务指标响应时间变长,通常会查看相关模块指标是否有异常。但是机器指标繁多,操作系统有CPU、网络等20多个指标,网交系统有几百个机器、几千个指标,如何从中快速定位异常机器?相比于传统阈值、人工查看历史数据的方式,AIOps能够在业务系统关键指标出现异常时,快速定位到是由底层哪个基础组件导致的,大幅缩减工作量。
首先,问题机器与历史时间点进行对比,查看历史时间节点是否发生突变;其次,问题机器与同一时间段、同一类型的其他机器进行对比,发现该问题机器带来的异常。检测过程中会运用到周期检测、极值检测、轻量算法以及同类型机器相比用的聚类算法。
下面分析一个典型案例。某天运维人员查询到某功能号平均延时增高达到200毫秒,明显超出基带合理范围。业务明细多维定位结果显示,某台机器的交易处理平均延时升高。进一步挖掘发现,在故障时段内每个账户查询时间均异常升高,且该机器system CPU使用率在故障时段内异常升高,判断由于该机器性能问题导致查询时间升高。深入排查发现,该机器所属宿主机异常,及时漂移到其他宿主机上,但是新宿主机性能与原宿主机存在差距,表现为同等业务量条件下CPU使用率增高。此案例中,业务明细多维定位准确定位到故障机器,帮助管理员快速锁定异常排查方向。
日志异常检测。日志是运维工作的核心,很多交易明细和异常根因潜藏在异常日志里面。但日志异常检测难点在于,日志量大、格式复杂、无效日志多。比如机器登录访问的连接失败都是“error”,如果不做判断或筛选,这种告警就毫无意义,会给日志异常检测带来困扰。这是我们正在努力建设的方向,期望通过算法学习挖掘出真正有效的日志关键字,实现对海量运维数据监控日志的问题发现。
数据展示。交易链路展示,便于管理员查看具体的交易明细;官方看板,直观体现某个业务系统,包括机器性能指标、业务黄金指标。当某个功能号、某个端口宕了,会在看板上直接标识异常,帮助运维管理员快速发现问题,同时通过企业微信向运维人员推送告警,做到告警准确发现和及时通知。