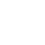大模型帮你给程序打日志|ICSE24论文分享
发布时间:2024-03-01 13:50:00
本文为香港中文大学(深圳)助理教授贺品嘉老师在论文闪电分享环节的演讲内容整理。
分享论文:UniLog: Automatic Logging via LLM and In-Context Learning基于上下文学习的自动化日志语句生成研究
非常荣幸能来跟各位专家老师和同学探讨一下我们近期在软件日志上的一些进展,今天的内容主要分三个部分。
背 景
我们的研究重点是日志语句的生成。众所周知,日志是运维的关键数据资源。日志语句的质量直接关系到日志分析的效果。优质的日志语句能够显著提升数据的可用性和分析的准确性,因此,确保程序记录的日志信息和开发者所收集的日志内容都高质量至关重要。

什么是日志语句?人们通常认为日志语句是开发者嵌入在代码中,用于在程序运行时记录信息的代码语句。例如,如下图下方框内的代码段所示,第四行即一个典型的日志语句,它会在程序执行时被触发并捕捉运行状态。本研究关注的问题就是在给定函数上下文的前提下如何自动为代码片段生成日志。这个问题可以分为几个步骤进行解析:首先确定在代码的哪个部位插入日志语句;接着确定该语句需包含哪些内容;然后选择合适的日志级别,如info、debug或warning等;最后决定需要记录哪些变量和信息。

日志生成问题已经被研究了许多年,最早始于2015年我们与微软的合作。最初的研究首先聚焦于“Where to log”问题,即如何判定在代码的哪个部分记录日志。最初这个问题的任务设置相对简单,其主要目标是判断给定的代码片段,例如try-catch block或者return value check block,是否应该添加日志语句。其预期的输出是一个布尔值,即“是”或“否”。随后,学术界和产业界不断有其他论文跟进和探索,研究了日志生成领域下的不同问题。例如我们应该记录什么内容的日志,以及具体应该在代码的哪一行添加日志等问题。
尽管这么多年来的研究取得了一些进展,但过去的研究仍存在一定的局限性。大多数研究工作会将问题拆解为几个子任务来解决,每篇论文通常只关注一个子任务。如前述图例,研究者通常把日志语句生成任务划分为三个部分:首先是确定在哪一行添加日志,比如上图例子中是在第四行添加日志;其次是定义日志的级别,例如上图代码中“log”后面的级别是“info”;最后是决定记录哪些详细信息,如上图所示的“disconnect”事件。然而,这些解决单一子任务的方法通常无法实用。当我们尝试将研究应用到产业界时,通常需要将这些不同的日志生成子任务结合起来构成一个完整的任务,并通过一个综合的日志生成解决方案来解决现实日志生成问题。
实现方法

现在,有了大模型之后,我们可以考虑的是,把这些任务组合起来端到端处理。近期我们和微软合作探索的一个工作叫UniLog。如上图,我们希望分析上面的代码片段之后,可以自动得出右下角内容,它包括语句的位置信息以及整个日志语句。
UniLog是第一个基于上下文学习 (in-context learning, ICL) 的日志记录框架,提供了新的日志记录范式:将所有日志记录的细分任务统一构建成一个文本生成任务,端到端地实现日志记录。
实现思路如上图所示,下方蓝色框里是给到的程序输入,即一段尚未加入日志语句的代码。接到该代码片段后,UniLog会利用历史代码库中已含日志语句的代码段作为参考,并将其与待注入日志的目标代码一同送入大规模语言模型中进行分析。右下角框里的是我们期望大语言模型告诉我们的结果,它包括行号以及具体带日志的代码片段。

具体而言,UniLog生成提示词的过程如上图所示。可见,UniLog从左上角的包含日志语句的历史代码片段中抽取日志语句,并把行号加在每行代码的最前面。之后,被提取了日志语句的代码片段将会作为参考样例,而日志语句本身将会作为样例的标签,以提供监督信息。需要注意的是我们把行号放在代码每一行的最前面,是因为想要利用大语言模型的文本生成能力,把行号也作为模型文本结果进行输出,过往的许多工作会把where to log的任务建模成一个位置的多分类的任务。相比之下,UniLog将位置预测建模成行号生成任务的方式更贴近大语言模型的文本生成补全的训练目标。
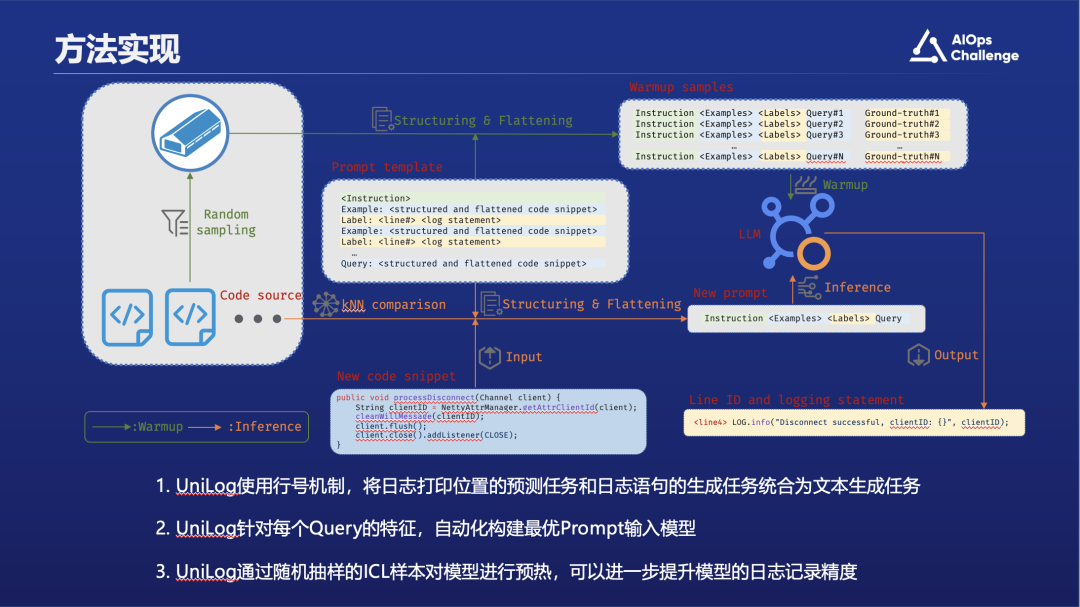
在处理完所有参考样例和他们的标签之后,UniLog将会把它们拼接在同样预处理好的目标代码段前,组装成一个完整的提示词。之后,UniLog将会提交提示词给大语言模型进行生成。生成的结果同样是如图片右上角所示的包含行号的日志语句。除了前面介绍的提示词相关的知识以外,我们还会用大模型做预热。
评估结果
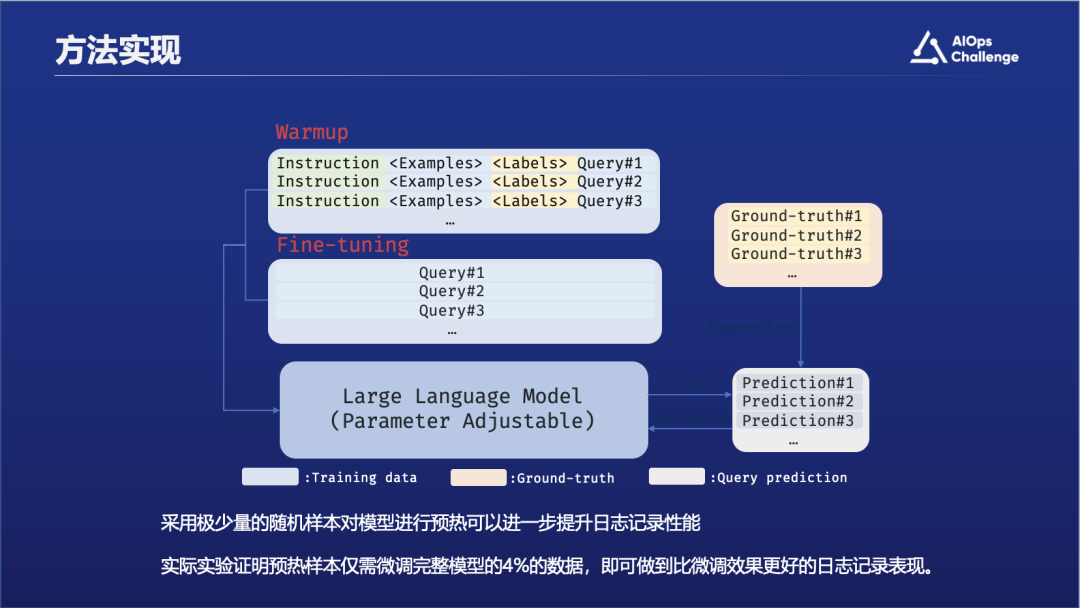
评估结果表明,UniLog通过一体化三个子任务——将行号置于输出之前——显著提高了性能。这种策略促使大型语言模型不仅准确预测日志应添加的位置,还同时产生了日志内容,较之前的方法实现了明显的效果提升。
上图表格里展示了不同的指标,比如PA是生成日志位置的精确度,LA是日志级别的精确度等等。
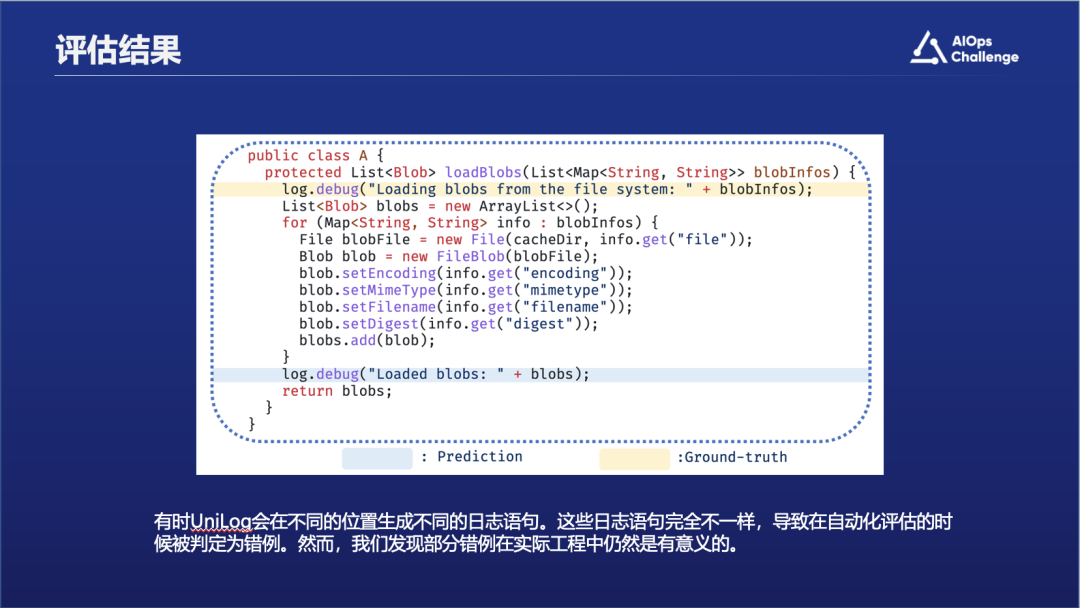
除了定量指标,我们还深入分析了自动评估下的失败案例,以揭示大型语言模型在自动化评估指标中生成的"错误"样本的特点。有趣的是,我们发现模型生成的日志语句虽与Ground-truth不同,但它们仍可提供有价值的视角。
以图中所示例子,黄色背景标注的代码行表示Ground-truth中的日志内容——"Loading blobs from the file system"。而下方蓝色背景的行展示了大语言模型生成的日志语句。尽管该语句与Ground-truth有所出入,并在评估中被认作是错误案例,它实际上也包含了有益信息。具体而言,模型产生的语句记录的是blob对象实例化后的数据,而非Ground-truth中记录的实例化前的元数据。这两种日志语句均能够提供关键的blob对象信息。因此,在自动评估中不符合预设标准的用例可能仍然有潜力向开发者提供可用的信息。